Contents
对象/关系数据库映射(ORM)
ORM全称是Object/Relation Mapping,对象/关系数据库映射。ORM可理解成一种规范,它概述了这类框架的基本特征:完成面向对象的编程语言到关系数据库的映射。
ORM基本映射方式
- 数据表映射类:持久化类被映射到一个数据表。
- 数据表的行映射对象:持久化类会生成很多实例,每个实例就对应数据表中的一行记录。
- 数据表的列映射对象的属性。
流行的ORM框架
- JPA:JPA只是一种ORM规范,并不是ORM产品。提供接口,而不是实现。所以如果面向JPA编程,那么程序即可在各种ORM框架之间自由切换。
- Hibernate
- iBATIS
- TopLink
Hibernate入门
Hibernate下载和安装
从 http://hibernate.org 进行下载。
将hibernate[version].jar和lib路径下的required、bytecode、jpa子目录下所有JAR包添加到应用的类加载路径中。Hibernate底层依然基于JDBC,所以JDBC对应的驱动也要添加到类加载路径中。
Hibernate的数据库操作
ORM框架中非常重要的媒介:PO(Persistent Object,持久化对象)。持久化对象的作用是完成持久化操作,简单说,通过该对象可对数据执行增删改查操作–以面向对象的方式操作数据库。
Hibernate使用POJO(普通、传统Java对象)作为PO
News.java
1 | public class News{ |
News.hbm.xml:
1 |
|
Hibernate配置文件hibernate.cfg.xml
1 |
|
Hibernate并不推荐DriverManager来连接数据库,而是推荐使用数据源来管理数据库连接,这样能保证更好的性能。Hibernate推荐使用C2P0数据源。
数据源是一种提高数据库连接性能的常规手段,数据源会负责维持一个数据库连接池,当程序创建数据源实例时,系统会一次性地创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行数据库访问时,无须重新获得数据库连接,而是从连接池中取出一个空闲的数据库连接。当程序使用数据库连接访问数据结束后,无须关闭数据库连接,而是将数据库连接归还给连接池即可,通过这种方式可以避免频繁地获取数据库连接、关闭数据库连接所导致的性能下降。
完成消息的插入操作
1 | //实例化Configuration, configure方法加载hibernate.cfg.xml文件 |
PO只有在Session的管理下才可完成数据库访问。为了使用Hibernate进行持久化操作,通常有如下操作步骤。
- 开发持久化类,由POJO加映射文件组成
- 获取Configuration
- 获取SessionFactory
- 获取Session,打开事务
- 用面向对象的方式操作数据库
- 关闭事务,关闭Session
随PO与Session的关联关系,PO有如下三种状态
- 瞬态:PO从未与Session关联
- 持久化:PO实例与Session关联起来,且该实例对应到数据库记录。
- 脱管:PO实例曾经与Session关联,但因为Session关闭等原因,PO实例脱离Session的管理。
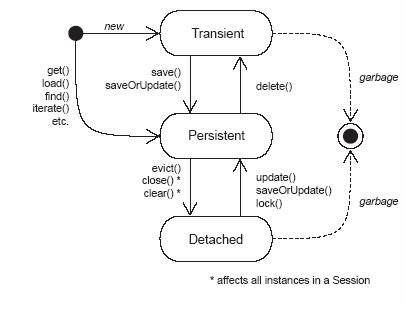
对PO的操作必须在Session管理下才能同步到数据库。Session由SessionFactory工厂产生,SessionFactory是数据库编译后的内存镜像,通常一个应用对应一个SessionFactory对象。SessionFactory对象由Configuration对象产生,Configuration对象负责加载Hibernate配置文件。
在Eclipse中使用Hibernate
Hibernate官方提供HibernateTools插件。
hibernate.cfg.xml文件通常在src目录下。
如果希望显示sql语句,自动建表可以在配置文件hibernate.cfg.xml中添加hibernate.show_sql、hibernate.format_sql和hibernate.hbm2ddl.auto
Hibernate体系结构
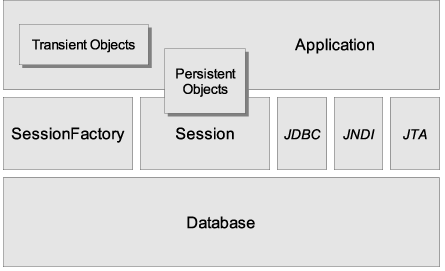
- SessionFactory:这是Hibernate的关键对象,它是单个数据库映射关系经过编译后的内存镜像,它也是线程安全的。它是生成Session的工厂,本身要应用到ConnectionProvider,该对象可以在进程和集群的级别上,为那些事务之间可以重用的数据提供可选的二级缓存。
- Session:它是应用程序和持久存储层之间交互操作的一个单线程对象。它也是Hibernate持久化操作的关键对象,所有的持久化对象必须在Session的管理下才能够进行持久化操作。此对象的生存周期很短,其隐藏了JDBC连接,也是Transaction 的工厂。Session对象有一个一级缓存,现实执行Flush之前,所有的持久化操作的数据都在缓存中Session对象处。
- 持久化对象:系统创建的POJO实例一旦与特定Session关联,并对应数据表的指定记录,那该对象就处于持久化状态,这一系列的对象都被称为持久化对象。程序中对持久化对象的修改,都将自动转换为持久层的修改。持久化对象完全可以是普通的Java Beans/POJO,唯一的特殊性是它们正与Session关联着。
- 瞬态对象和脱管对象:系统进行new关键字进行创建的Java 实例,没有Session 相关联,此时处于瞬态。瞬态实例可能是在被应用程序实例化后,尚未进行持久化的对象。如果一个曾经持久化过的实例,但因为Session的关闭而转换为脱管状态。
- 事务(Transaction):代表一次原子操作,它具有数据库事务的概念。但它通过抽象,将应用程序从底层的具体的JDBC、JTA和CORBA事务中隔离开。在某些情况下,一个Session 之内可能包含多个Transaction对象。虽然事务操作是可选的,但是所有的持久化操作都应该在事务管理下进行,即使是只读操作。
- 连接提供者(ConnectionProvider):它是生成JDBC的连接的工厂,同时具备连接池的作用。他通过抽象将底层的DataSource和DriverManager隔离开。这个对象无需应用程序直接访问,仅在应用程序需要扩展时使用。
- 事务工厂(TransactionFactory):他是生成Transaction对象实例的工厂。该对象也无需应用程序的直接访问。
深入Hibernate的配置文件
使用hibernate.properties作为配置文件
需要通过addResource方法添加映射文件
new Configuration().addResource("News.hbm.xml")。也可以通过addClass()方法添加持久化类new Configuration().addClass(lee.Nuews.class)此时映射文件应该放在类文件相同的包路径下。Hibernate自己会去搜索。使用hibernate.cfg.xml作为配置文件
hibernate.cfg.xml文件中已经添加了Hibernate映射文件。
new Configuration().configure()不用配置文件创建Configuration实例
使用下面三个方法
1
2
3Configuration addResource(String resourceName)
Configuration setProperties(Properties properties)
Configuration setProperty(String propertyName, String value)
JDBC连接属性
所有Hibernate属性的名字和语义都在org.hibernate.cfg.Environment中定义。
- hibernate.connection.driver_class:指定连接数据库所用的驱动。
- hibernate.connection.url:指定连接数据库的url,hibernate连接的数据库名。
- hibernate.connection.username:该属性是可选的。
- hibernate.connection.passowrd:该属性是可选的。
- hibernate.connection.pool_size:设置Hibernate数据库连接池的最大并发连接数。
- hibernate.dialect:设置连接数据库所使用的方言。
Hibernate自带的连接池仅有测试价值,实际项目中使用C3P0或Proxool连接池。
数据库方言
| 关系型数据库 | 方言 |
|---|---|
| DB2 | org.hibernate.dialect.DB2Dialect |
| DB2 AS/400 | org.hibernate.dialect.DB2400Dialect |
| DB2 OS390 | org.hibernate.dialect.DB2390Dialect |
| PostgreSQL | org.hibernate.dialect.PostgreSQLDialect |
| MySQL | org.hibernate.dialect.MySQLDialect |
| MySQL with InnoDB | org.hibernate.dialect.MySQLInnoDBDialect |
| MySQL with MyISAM | org.hibernate.dialect.MySQLMyISAMDialect |
| Oracle (any version) | org.hibernate.dialect.OracleDialect |
| Oracle 9i | org.hibernate.dialect.Oracle9iDialect |
| Oracle 10g | org.hibernate.dialect.Oracle10gDialect |
| Sybase | org.hibernate.dialect.SybaseDialect |
| Sybase Anywhere | org.hibernate.dialect.SybaseAnywhereDialect |
| Microsoft SQL Server | org.hibernate.dialect.SQLServerDialect |
| SAP DB | org.hibernate.dialect.SAPDBDialect |
| Informix | org.hibernate.dialect.InformixDialect |
| HypersonicSQL | org.hibernate.dialect.HSQLDialect |
| Ingres | org.hibernate.dialect.IngresDialect |
| Progress | org.hibernate.dialect.ProgressDialect |
| Mckoi SQL | org.hibernate.dialect.MckoiDialect |
| Interbase | org.hibernate.dialect.InterbaseDialect |
| Pointbase | org.hibernate.dialect.PointbaseDialect |
| FrontBase | org.hibernate.dialect.FrontbaseDialect |
| Firebird | org.hibernate.dialect.FirebirdDialect |
JNDI数据源的连接属性
JNDI: Java Naming Directory Interface,Java命名目录接口。
- hibernate.connection.datasource:指定数据源JNDI名字。
- hibernate.jndi.url:指定JNDI提供者的URL,该属性是可选的。如果JNDI与HIbernate持久化访问的代码处在同一个应用中。则无须指定该属性。
- hibernate.jndi.class:指定JND InitialContextFactory的实现类,该属性也是可选的。如果JNDI与HIbernate持久化访问的代码处在同一个应用中。则无须指定该属性。
- hibernate.connection.username:该属性是可选的。
- hibernate.connection.passowrd:该属性是可选的。
虽然设置数据库方言并不是必需的,但对于优化持久层访问很有必要。
Hibernate事务属性
- hibernate.transaction.factory_class:指定Hibernate所用的事务工厂的类型,该属性值必须是TransactionFactory的直接或间接子类。
- jta.UserTransaction:该属性值是一个JNDI名,Hibernate将使用JTATransactionFactory从应用服务器获取JTA UserTransaction。
- hibernate.transaction.manager_lookup_class:该属性值应为一个TransactionManagerLookup类名,当使用JVM级别的缓存时,或在JTA环境中使用hilo生成器策略时,需要该类。
- hibernate.transaction.flush_before_completion:指定Session是否在事务完成后自动将数据刷新到底层受苦。该属性值只能为true或false。现在更好的方法是使用Context相关的Session管理。
- hibernate.transaction.auto_close_session:指定是否在事务结束后自动关闭Session。该属性只能是true或false。现在更好的方法是使用Context相关的Session管理。
二级缓存相关属性
- hibernate.cache.provider_class:该属性用于设置二级缓存CacheProvider的类名
- hibernate.cache.user_minimal_puts:
- hibernate.cache.use_second_level_cache:
- hibernate.cache.query_cache_factory:
- hibernate.cache.region_prefix:
- hibernate.cache.use_structured_entries:
外连接抓取属性
将hibernate.max_fetch_depth设为0,将在全局范围内禁止外连接抓取,设为1或更高值能启用N-1或1-1的外连接抓取。除此之外,还应该在映射文件中通过fetch=”join”来指定这种外连接抓取。
其他常用的配置属性
- hibernate.show_sql:是否在控制台打印Hibernate生成的sql语句。
- hibernate.format_sql:是否将SQL语句格式化。
- hibernate.use_sql_comments:是否在Hibernate生成的SQL语句中添加有助于调试的注释。前三个取值只能是true或false
- hibernate.jdbc.fetch_size:指定JDBC抓取数量的大小,它可接受一个整数值,其实质是调用Statement.setFetchSize()方法
- hibernate.jdbc.batch_size:指定Hibernate使用JDBC2的批量更新的大小,它接受一个整数值,建议取5到30之间的值。
- hibernate.connection.autocommit:设置是否自动提交。通常不建议打开自动提交。
- hibernate.hbm2ddl.auto:设置当创建SessionFactory时,是否根据映射文件自动建立数据库表。如果使用create-drop值,显示关闭SessionFactory时,将Drop刚建的数据表。该属性可以为update、create和create-drop三个值。
深入理解持久化对象
持久化类的要求
- 提供一个无参数的构造器
- 提供一个标识属性,标识属性通常映射数据库表的主键字段。可以是任何名字,可以使用基本类型及其包装类,java.lang.String,java.util.Date。如果是联合主键,甚至可以用一个用户自定义的类,也可以不指定任何标识属性,而在配置文件中将多个普通类型映射成一个联合主键,但通常不推荐这么做。主键建议使用包装类型而不是基本类型。
- 没有标识可能导致Hibernate很多功能没法使用。Hibernate建议使用可以为空的类型来作为标识属性的类型,因此应该尽量避免使用基本数据类型。
- 为持久化类的每个属性提供setter和getter方法。Hibernate默认采用属性方式访问持久化类的属性。setX、getX、isX是被认可的。
- 使用非final的类。同时应避免在非final类中声明public final的方法。如果有这种方法,必须通过设置lazy=”false”来明确地禁用代理。
- 重写equals()和hashCode()方法。需要放入Set中(当进行关联映射时,推荐这么做),通常是使用判断标志值的方法。遗憾的是,对采用自动生成标识的对象不能使用这种方法。Hibernate仅为那些持久化对象指定标识值,一个新创建的实例将不会有任何标识值,通过保存一个对象将会给它赋标识值。如果equals()和hashCode()是基于标识值的,则其hashCode返回值会发生改变,这将违反Set规则。当我们想要重用脱管实例时,该实例所属的持久化类也应该重写equals()和hashCode()
持久化对象的状态
- 瞬态:对象由new操作符创建,且尚未与Hibernate Session 关联的对象。不会被持久化到数据库中,也不会被赋予持久化标识。使用Hibernate Session可以将其变为持久化状态。
- 持久化:实例对应到数据库记录,并拥有一个持久化标识。持久化对象可以是刚刚保存的也可以是刚加载的,必须与指定的Hibernate Session关联。Hibernate会检测到处于持久化状态对象的改动,在当前操作执行完成时将对象数据写会数据库,不需要手动update。
- 脱管:某个实例曾经处于持久化状态,但随着与之关联的Session关闭,该对象处于脱管状态。
改变持久化对象状态的方法
save()和persist()方法
- 如果News的标识属性是generated,也就是说指定了主键生成器,那么Hibernate将会在执行save方法时自动生成标识属性值,并将该标识属性值分配给该News对象。
- 如果News的标识属性是assigned类型的,或者是联合主键,那么该标识属性值应当在调用save之前手动赋给News对象。
Hibernate之所以提供与save( )功能几乎完全类似的persist( )方法,一方面是为了照顾JPA的用法习惯。另一方面save和persist还有一个区别:使用save( )方法保存持久化对象时,该方法返回该持久化对象的标识属性值即对应记录的主键值;但persist( )方法保存持久化对象时,没有任何返回值。因为save方法需要立即返回持久化对象的标识属性值,所以程序执行save( )方法时会立即将持久化对象对应的数据插入数据库。而persist方法则保证当它在一个事物外部被调用时,并不立即转换成insert语句,这个功能是很有用的,尤其当我们封装一个长会话流程的时候,persist就显得尤为重要了。
load( )与get( ):
也可以通过load( )来加载一个持久化实例,这种加载就是根据持久化类的标识属性值加载持久化实例——其实质就是根据主键从数据表中加载一条新记录。News n=session.load(News.class,new Integer(pk));pk就是需要加载的持久化实例的标识属性。
如果没有匹配的数据库记录,load( )方法可能抛出HibernateException异常;如果我们在类映射文件中指定了延迟加载,则load( )方法会返回一个未初始化的代理对象,这个代理对象并没有装载数据记录,直到程序调用该代理对象的某方法时,Hibernate才会去访问数据库。
如果希望在某对象中创建一个指向另一个对象的关联,又不想在从数据库中装载该对象的同时装载相关联的所有对象,这种延迟加载的方式就非常有用了。
与load( )方法类似的是get( )方法,get( )方法也用于根据主键装载持久化实例,但get( )方法会立刻访问数据库,如果没有对应的记录,get( )方法返回null,而不是返回一个代理对象。
一旦加载了该持久化实例后,该实体就处于持久化状态,在代码中对持久化实例所做的修改,例如:n.setTitle(“新标题”);这种修改将被保存到数据库,对标题的修改被映射成修改数据表的特定行的特定列。
程序对持久化实例所做的修改会在Session flush之前被自动保存到数据库,无需程序调用其他方法(不需要调用update方法)来将修改持久化。也就是说,修改对象最简单的方法就是在Session处于打开状态时load它,然后直接修改即可。
对于一个曾经持久化过的、但现在已脱离Session管理的持久化对象,我们把它称为处于脱管状态。当我们修改脱管对象的状态后,程序应该使用新的Session来保存这些修改。Hibernate提供了update( )、merge( )和updateOrSave( )等方法来保存这些修改。
1 | News n=firstSession.load(News.class,new Integer(pk)); |
当我们用另一个Session来保存这种修改后,该脱管对象再次回到Session的管理之下,也就再次回到持久化状态。
当需要使用update( )来保存程序对持久化对象所做的修改时,如果不清楚该对象是否曾经持久化过,那么程序可以选择使用updateOrSave( )方法,该方法自动判断该对象是否曾经持久化,如果曾经持久化过,就使用update方法,否则将使用save操作。
merge( )方法也可将程序对脱管对象所做的修改保存到数据库,但merge方法与update方法最大的区别就是:merge( )方法不会持久化给定对象。举例来说,当我们执行session.update(a)代码后,a对象将会变成持久化状态;而执行session.merge(a)代码后,a对象依然不是持久化状态,a对象依然不会被关联到Session上。
当程序使用merge()方法来保存程序对脱管对象所做的修改时,如果Session中存在相同持久化标识的持久化对象,merge()方法里提供对象的状态将覆盖原有持久化实例的状态。如果Session中没有相应的持久化实例,则尝试从数据库中加载,或创建新的持久化实例,最后返回持久化实例。
merge()方法作用只是将当前对象的状态信息保存到数据库,并不会将该对象转换为持久化状态。
当我们使用load()和get()方法来加载持久化对象时,还可以指定一个”锁模式”参数。
save():保存持久化对象,在数据库中新增加一条数据
saveOrUpdate()保存或者是更新,该方法根据id标签的unsaved-value属性值决定执行新增加一条记录或者是更新。
get()根据标识符属性获得一个持久化对象,如果未找到,则返回null
load()该方法根据标识符属性加在一个持久化对象,如果未找到,则抛出异常
update() 该方法对托管状态的对象重新完成持久化,更新数据库中的数据
delete()删除数据库中的一条记录,不过需要先使用get() or load() 获取持久化对象
close()关闭当前的session对象,并且清空该对象中的数据
evict()用于清除session缓存中的某一个对象
clear()清除Session中的所有缓存对象。
映射
在Hibernate中使用Annotation,跟以前xml配置的方式相比:
- 仍然需要cfg.xml
- 在cfg.xml中需要配置要通过注解来配置的类,例如:
1
2<mapping package="test.animals"/>
<mapping class="test.Flight"/> - 程序里面,原来的new Configuration()的地方,可以变成:new AnnotationConfiguration(),也可以不用改。
- 可以通过编程的方式来添加要映射的类,例如:
1
2new AnnotationConfiguration().addPackage("test.animals")
.addAnnotatedClass(Flight.class)
映射实体
@Entity,注册在类头上,将一个类声明为一个实体bean(即一个持久化POJO类) 。
@Table,注册在类头上,注解声明了该实体bean映射指定的表(table )。
@Table元素有name、schema、catalog 和 uniqueConstraints属性,如果需要可以指定相应的值. 结合使用@UniqueConstraint注解可以定义表的唯一约束(unique constraint) (对于绑定到单列的唯一约束,请参考@Column注解)
1
@Table(name="tbl_sky", uniqueConstraints = {@UniqueConstraint(columnNames={"month", "day"})})
上面这个例子中,在month和day这两个字段上定义唯一约束. 注意columnNames数组中的值指的是逻辑列名.
映射属性
在对一个类进行注解时,你可以选择对它的的属性或者方法进行注解,根据你的选择,Hibernate的访问类型分别为 field或property. EJ3规范要求在需要访问的元素上进行注解声明,例如,如果访问类型为 property就要在getter方法上进行注解声明, 如果访问类型为 field就要在字段上进行注解声明.应该尽量避免混合使用这两种访问类型. Hibernate根据@Id 或 @EmbeddedId的位置来判断访问类型.
@Id用来注册主属性,@GeneratedValue用来注册主属性的生成策略,@Column用来注册属性,@Version用来注册乐观锁,@Transient用来注册不是属性。
@Transient注册在多余的属性或多余的getter上,但是必须与以上的@Column等对应。
Hibernate Annotations还支持将内置的枚举类型映射到一个顺序列(保存了相应的序列值) 或一个字符串类型的列(保存相应的字符串).默认是保存枚举的序列值, 但是你可以通过@Enumerated注解来进行调整
在核心的Java API中并没有定义时间精度(temporal precision). 因此处理时间类型数据时,你还需要定义将其存储在数据库中所预期的精度. 在数据库中,表示时间类型的数据有DATE, TIME, 和 TIMESTAMP三种精度(即单纯的日期,时间,或者两者兼备). 可使用@Temporal注解来调整精度.
@Lob注解表示属性将被持久化为Blob或者Clob类型, 具体取决于属性的类型, java.sql.Clob, Character[], char[] 和 java.lang.String这些类型的属性都被持久化为Clob类型, 而java.sql.Blob, Byte[], byte[] 和 serializable类型则被持久化为Blob类型.
非主属性
@Column
标识属性对应的字段,示例:@Column(name=”userName”)
1 | @Column( |
(1) name 可选,列名(默认值是属性名)
(2) unique 可选,是否在该列上设置唯一约束(默认值false)
(3) nullable 可选,是否设置该列的值可以为空(默认值false)
(4) insertable 可选,该列是否作为生成的insert语句中的一个列(默认值true)
(5) updatable 可选,该列是否作为生成的update语句中的一个列(默认值true)
(6) columnDefinition 可选: 为这个特定列覆盖SQL DDL片段 (这可能导致无法在不同数据库间移植)
(7) table 可选,定义对应的表(默认为主表)
(8) length 可选,列长度(默认值255)
(9) precision 可选,列十进制精度(decimal precision)(默认值0)
(10) scale 可选,如果列十进制数值范围(decimal scale)可用,在此设置(默认值0)
如果某属性没有注解,该属性将遵守下面的规则:
无注解之属性的默认值
如果属性为单一类型,则映射为@Basic
否则,如果属性对应的类型定义了@Embeddable注解,则映射为@Embedded
否则,如果属性对应的类型实现了Serializable, 则属性被映射为@Basic并在一个列中保存该对象的serialized版本
否则,如果该属性的类型为java.sql.Clob 或 java.sql.Blob,则作为@Lob并映射到适当的LobType.
主属性
@Id,标识这个属性是实体类的唯一识别的值。
注意:这个注解只能标注单一列构成的主键,有两个字段组成的联合主键由其他注解标识。
@Id,只是标识这个属性是主键,但是并没有指出其生成策略
如果仅仅写出@Id,即是使用默认生成策略,如:
JPA通用策略生成器
JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO,默认AUTO
- AUTO - 可以是identity column类型,或者sequence类型或者table类型,取决于不同的底层数据库.
- TABLE - 使用一个特定的数据库表格来保存主键
- IDENTITY - 主键由数据库自动生成(主要是自动增长型)
- SEQUENCE - 根据地层数据库的序列来生成主键,条件是数据库支持序列,主要是Oracle
hibernate主键策略生成器
hibernate提供多种主键生成策略,有点是类似于JPA,有的是hibernate特有:
- native: 对于 oracle 采用 Sequence 方式,对于MySQL 和 SQL Server 采用identity(自增主键生成机制),native就是将主键的生成工作交由数据库完成,hibernate不管(很常用)。
- uuid: 采用128位的uuid算法生成主键,uuid被编码为一个32位16进制数字的字符串。占用空间大(字符串类型)。
- hilo: 使用hilo生成策略,要在数据库中建立一张额外的表,默认表名为hibernate_* unique_key,默认字段为integer类型,名称是next_hi(比较少用)。
- assigned: 在插入数据的时候主键由程序处理(很常用),这是
元素没有指定时的默认生成策略。等同于JPA中的AUTO。 - identity: 使用SQL Server 和 MySQL 的自增字段,这个方法不能放到 Oracle 中,Oracle 不支持自增字段,要设定sequence(MySQL 和 SQL Server 中很常用)。等同于JPA中的INDENTITY。
- select: 使用触发器生成主键(主要用于早期的数据库主键生成机制,少用)。
- sequence: 调用底层数据库的序列来生成主键,要设定序列名,不然hibernate无法找到。
- seqhilo: 通过hilo算法实现,但是主键历史保存在Sequence中,适用于支持 Sequence 的数据库,如 Oracle(比较少用)
- increment: 插入数据的时候hibernate会给主键添加一个自增的主键,但是一个hibernate实例就维护一个计数器,所以在多个实例运行的时候不能使用这个方法。
- foreign: 使用另外一个相关联的对象的主键。通常和
联合起来使用。 - guid: 采用数据库底层的guid算法机制,对应MYSQL的uuid()函数,SQL Server的newid()函数,ORACLE的rawtohex(sys_guid())函数等。
- uuid.hex: 看uuid,建议用uuid替换。
- sequence-identity: sequence策略的扩展,采用立即检索策略来获取sequence值,需要JDBC3.0和JDK4以上(含1.4)版本
hibernate提供了多种生成器供选择,基于Annotation的方式通过@GenericGenerator实现.
hibernate每种主键生成策略提供接口org.hibernate.id.IdentifierGenerator的实现类,如果要实现自定义的主键生成策略也必须实现此接口
如果想使用Oracle支持的sequence取主键,必须通过@GeneratedValue来指定生成策略,而由@SequenceGenerator指定如何使用sequence。
1 | @Id |
@SequenceGenerator定义
1 | ({TYPE, METHOD, FIELD}) |
name属性表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的”generator”值中。
sequenceName属性表示生成策略用到的数据库序列名称。
initialValue表示主键初识值,默认为0。
allocationSize表示每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。
自定义主键生成策略
自定义主键生成策略,由@GenericGenerator实现。
hibernate在JPA的基础上进行了扩展,可以用一下方式引入hibernate独有的主键生成策略,就是通过@GenericGenerator加入的。
比如说,JPA标准用法
1 | @Id |
就可以用hibernate特有以下用法来实现
1 | @GeneratedValue(generator = "paymentableGenerator") |
@GenericGenerator有三个属性
- name属性指定生成器名称。
- strategy属性指定具体生成器的类名。
- parameters得到strategy指定的具体生成器所用到的参数。
乐观锁和不用持久化
- @Version
标识这个属性用来映射乐观锁的version。entity manager使用该字段来检测更新冲突(防止更新丢失,请参考last-commit-wins策略).
根据EJB3规范,version列可以是numeric类型(推荐方式)也可以是timestamp类型. Hibernate支持任何自定义类型,只要该类型实现了UserVersionType. - @Transient
标识这个属性不用持久化
复合属性—组件映射
@Embeddable 【小对象的头上】
标识实体中可以定义一个嵌入式组件(embedded component)。组件类必须在类一级定义@Embeddable注解。
@Embedded 【大对象的属性头上】
引用定义的小对象。
使用@Embedded和 @AttributeOverride注解可以覆盖该属性对应的嵌入式对象的列映射
1
2
3
4
5@Embedded
@AttributeOverrides( {
@AttributeOverride(name="iso2", column = @Column(name="bornIso2") ),
@AttributeOverride(name="name", column = @Column(name="bornCountryName") ) } )
Country bornIn;
复合属性—复合主键
下面是定义组合主键的几种语法:
将组件类注解为@Embeddable,并将组件的属性注解为@Id
将组件的属性注解为@EmbeddedId
将类注解为@IdClass,并将该实体中所有属于主键的属性都注解为@Id
@Embeddable 【小对象的头上】
标识实体中可以定义一个嵌入式组件(embedded component)。组件类必须在类一级定义@Embeddable注解。
注意:如果这个小对象作为复合主键,一定要实现Serializable接口。这并不是注解决定的,而是Hibernate的主键都需要实现Serializable接口。@EmbeddedId 【大对象的属性头上】
引用定义的小对象作为主键。
注意:不需要再使用@Id注解。
集合映射
你可以对 Collection ,List (指有序列表, 而不是索引列表), Map和Set这几种类型进行映射. EJB3规范定义了怎么样使用@javax.persistence.OrderBy 注解来对有序列表进行映射: 该注解接受的参数格式:用逗号隔开的(目标实体)属性名及排序指令, 如firstname asc, age desc,如果该参数为空,则默认以id对该集合进行排序. 如果某个集合在数据库中对应一个关联表(association table)的话,你不能在这个集合属性上面使用@OrderBy注解. 对于这种情况的处理方法,请参考Hibernate Annotation Extensions. EJB3 允许你利用目标实体的一个属性作为Map的key, 这个属性可以用@MapKey(name=”myProperty”)来声明. 如果使用@MapKey注解的时候不提供属性名, 系统默认使用目标实体的主键. map的key使用和属性相同的列:不需要为map key定义专用的列,因为map key实际上就表达了一个目标属性。 注意一旦加载,key不再和属性保持同步, 也就是说,如果你改变了该属性的值,在你的Java模型中的key不会自动更新 (请参考Hibernate Annotation Extensions). 很多人被
Hibernate将集合分以下几类.
| 语义 | Java实现类 | 注解 |
|---|---|---|
| Bag 语义 | java.util.List, java.util.Collection | @org.hibernate.annotations.CollectionOfElements 或 @OneToMany 或 @ManyToMany |
| List 语义 | java.util.List | (@org.hibernate.annotations.CollectionOfElements 或 @OneToMany 或 @ManyToMany) 以及 @org.hibernate.annotations.IndexColumn |
| Set 语义 | java.util.Set | @org.hibernate.annotations.CollectionOfElements 或 @OneToMany 或 @ManyToMany |
| Map 语义 | java.util.Map | (@org.hibernate.annotations.CollectionOfElements 或 @OneToMany 或 @ManyToMany) 以及 (空 或 @org.hibernate.annotations.MapKey/MapKeyManyToMany(支持真正的map), 或 @javax.persistence.MapKey |
从上面可以明确地看到,没有@org.hibernate.annotations.IndexColumn 注解的java.util.List集合将被看作bag类.
EJB3规范不支持原始类型,核心类型,嵌入式对象的集合.但是Hibernate对此提供了支持
1 | public class City { |
上面这个例子中,City 中包括了以streetName排序的Street的集合. 而Software中包括了以codeName作为 key和以Version作为值的Map.
除非集合为generic类型,否则你需要指定targetEntity. 这个注解属性接受的参数为目标实体的class.
Hibernate Annotations还支持核心类型集合(Integer, String, Enums, ……)、 可内嵌对象的集合,甚至基本类型数组.这就是所谓的元素集合.
元素集合可用@CollectionOfElements来注解(作为@OneToMany的替代). 为了定义集合表(译注:即存放集合元素的表,与下面提到的主表对应),要在关联属性上使用@JoinTable注解, joinColumns定义了介乎实体主表与集合表之间的连接字段(inverseJoincolumn是无效的且其值应为空). 对于核心类型的集合或基本类型数组,你可以在关联属性上用@Column来覆盖存放元素值的字段的定义. 你还可以用@AttributeOverride来覆盖存放可内嵌对象的字段的定义. 要访问集合元素,需要将该注解的name属性值设置为”element”(“element”用于核心类型,而”element.serial” 用于嵌入式对象的serial属性).要访问集合的index/key,则将该注解的name属性值设置为”key”.
映射继承关系
EJB3支持三种类型的继承映射:
- 每个类一张表(Table per class)策略: 在Hibernate中对应
元素: - 每个类层次结构一张表(Single table per class hierarchy)策略:在Hibernate中对应
元素 - 连接的子类(Joined subclasses)策略:在Hibernate中对应
元素
你可以用 @Inheritance注解来定义所选择的策略. 这个注解需要在每个类层次结构(class hierarchy) 最顶端的实体类上使用.
每个类一张表
这种策略有很多缺点(例如:多态查询和关联),EJB3规范, Hibernate参考手册, Hibernate in Action,以及其他许多地方都对此进行了描述和解释. Hibernate使用SQL UNION查询来实现这种策略. 通常使用场合是在一个继承层次结构的顶端:
1 | @Entity |
这种策略支持双向的一对多关联. 这里不支持IDENTITY生成器策略,因为id必须在多个表间共享. 当然,一旦使用这种策略就意味着你不能使用 AUTO 生成器和IDENTITY生成器.
每个类层次结构一张表
整个继承层次结构中的父类和子类的所有属性都映射到同一个表中, 他们的实例通过一个辨别符(discriminator)列来区分.:
1 | @Entity |
在上面这个例子中,Plane是父类,在这个类里面将继承策略定义为 InheritanceType.SINGLE_TABLE,并通过 @DiscriminatorColumn注解定义了辨别符列(还可以定义辨别符的类型). 最后,对于继承层次结构中的每个类,@DiscriminatorValue注解指定了用来辨别该类的值. 辨别符列的名字默认为 DTYPE,其默认值为实体名(在@Entity.name中定义),其类型 为DiscriminatorType.STRING. A320是子类,如果不想使用默认的辨别符,只需要指定相应的值即可. 其他的如继承策略,辨别标志字段的类型都是自动设定的.
@Inheritance 和 @DiscriminatorColumn 注解只能用于实体层次结构的顶端.
连接的子类
当每个子类映射到一个表时, @PrimaryKeyJoinColumn 和@PrimaryKeyJoinColumns 注解定义了每个子类表关联到父类表的主键:
1 | @Entity |
以上所有实体都使用了JOINED策略, Ferry表和Boat表使用同名的主键. 而AmericaCupClass表和Boat表使用了条件 Boat.id = AmericaCupClass.BOAT_ID进行关联.
从父类继承的属性
有时候通过一个(技术上或业务上)父类共享一些公共属性是很有用的, 同时还不用将该父类作为映射的实体(也就是该实体没有对应的表). 这个时候你需要使用@MappedSuperclass注解来进行映射.
1 | @MappedSuperclass |
在数据库中,上面这个例子中的继承的层次结构最终以Order表的形式出现, 该表拥有id, lastUpdate 和 lastUpdater三个列.父类中的属性映射将复制到其子类实体. 注意这种情况下的父类不再处在继承层次结构的顶端.
注意:
注意,没有注解为@MappedSuperclass的父类中的属性将被忽略。
除非显式使用Hibernate annotation中的@AccessType注解, 否则将从继承层次结构的根实体中继承访问类型(包括字段或方法)。
这对于@Embeddable对象的父类中的属性持久化同样有效. 只需要使用@MappedSuperclass注解即可 (虽然这种方式不会纳入EJB3标准)。
可以将处在在映射继承层次结构的中间位置的类注解为@MappedSuperclass。
在继承层次结构中任何没有被注解为@MappedSuperclass 或@Entity的类都将被忽略。
你可以通过 @AttributeOverride注解覆盖实体父类中的定义的列. 这个注解只能在继承层次结构的顶端使用.
1 |
|
在上面这个例子中,altitude属性的值最终将持久化到Plane 表的fld_altitude列.而名为propulsion的关联则保存在fld_propulsion_fk外间列.
你可以为@Entity和@MappedSuperclass注解的类 以及那些对象为@Embeddable的属性定义 @AttributeOverride和@AssociationOverride.
关联关系映射
关联关系映射—简介
在hibernate中,支持对象之间的关联关系映射,这样可以减少我们的dao操作,操作一个对象的时候,就可以顺带操作它的关联对象。我们知道,hibernate支持三种关联关系,1:1,1:M,M:N。但,这只是对象之间的关系。数据库的设计当然也支持1:1,1:M,M:N三种关系。比如,我们经常说的1:M,就是把1这张表的主键拿到多那边做外键。但是,很多同学经常迷惑,为什么网上介绍的1:M,比我们讲的还要复杂的多?我们只需要
关联关系映射—数据库降级使用
标准的1:M
1 | +----------+ +----------+ |
标准的M:N
1 | +-----------+ +---------------+ +-----------+ |
将M:N的数据库设计降级为1:M使用
1 | +-----------+ +-----------------------+ +-----------+ |
关联关系映射—1:1—共享主键
标准的1:1
1 | +-----------+ +----------------+ |
XML的配置
主1 【tbl_product】:
1
<one-to-one name= "info" cascade="all"/>
从1 【tbl_product_info】:
1
2
3
4
5
6
7<id name= "uuid">
<generator class="foreign 【写死,使用外来生成策略】">
<param name="property">product 【引用自己的Java属性名】
</param>
</generator>
</id>
<one-to-one name= "product"/>注解的配置
主1 【tbl_product】:
1
2
3@OneToOne(cascade=CascadeType.ALL)
@PrimaryKeyJoinColumn
private ProductInfoModel info;从1 【tbl_product_info】:
1
2
3
4
5
6
7@Id
@Column
@GeneratedValue(generator="copy 【引用生成策略】")
@GenericGenerator(name="copy 【定义生成策略】",strategy="foreign 【写死,使用外来策略】",parameters=@Parameter(name="property",value="product 【引用自己的Java属性】"))
private int uuid;
@OneToOne(mappedBy="info 【引用对方的Java属性】")
private ProductModel product;
关联关系映射—1:M—外键
标准的1:M
1 | +----------+ +----------+ |
XML的配置
1 【tbl_parent】:
1
2
3
4<set name= "children">
<key column="puuid 【对方的数据库外键列名】"/>
<one-to-many class="cn.j avass.model.c.ChildModel 【对方的Java类名】"/>
</set>多 【tbl_child】:
1
<many-to-one name="parent" column="puuid 【自己的数据库外键列名】"/>
- 注解的配置
1 【tbl_parent】:多 【tbl_child】:1
2
3@OneToMany
@JoinColumn(name="puuid 【对方的数据库外键列名】")
private Set<ChildModel> children = new HashSet<ChildModel>();1
2
3@ManyToOne
@JoinColumn(name="puuid 【自己的数据库外键列名】")
private ParentModel parent;
关联关系映射—M:N—联接表
标准的M:N
1 | +-----------+ +---------------+ +-----------+ |
XML的配置
1
2
3
4
5<set name="courses" table="tbl_grade 【联接表】">
<key column="suuid 【联接表里代表自己的数据库字段名】"/>
<many-to-many column="cuuid 【联接表里代表对方的数据库字段名】"
class="cn.ja vass.model.e.CourseMode 【对方的类名】l"/>
</set>注解的配置
1
2
3
4
5
6
7@ManyToMany
@JoinTable(
name="tbl_grade 【联接表】",
joinColumns=@JoinColumn(name="suuid 【联接表里代表自己的数据库字段名】"),
inverseJoinColumns=@JoinColumn(name="cuuid 【联接表里代表对方的数据库字段名】" )
)
private Set<CourseModel> courses = new HashSet<CourseModel>();
关联关系映射—1:1—引用外键
标准的1:M
1 | +-----------+ +-----------------------+ |
XML的配置
主1 【tbl_product】:
1
<one-to-one name="info" foreign-key= "puuid 【对方的数据库外键列名】" cascade="all"/>
从1 【tbl_product_info】:
1
<many-to-one name="product" column="puuid 【自己的数据库外键列名】" unique="true 【写死】"/>
注解的配置
主1 【tbl_product】:
1
2@OneToOne(cascade=CascadeType.ALL,mappedBy="product 【对方的Java类属性名】")
private ProductInfoModel info;从1 【tbl_product_info】:
1
2
3@OneToOne
@JoinColumn(name="puuid 【自己的数据库外键列名】")
private ProductModel product;
关联关系映射—1:M—联接表
标准的1:M
1 | +-----------+ +-----------------------+ +-----------+ |
XML的配置
1 【tbl_parent 】:1
2
3
4
5
6
7
8<set name="children" table="tbl_parent_child 【联接表】">
<key column="puuid 【联接表里代表自己的数据库列名】"/>
<many-to-many column="cuuid 【联接表里代表对方的数据库列名】" unique="true 【写死】" class="cn.javass.model.d.ChildModel 【对方的Java类名】"/>
</set>
<join table="tbl_parent_child 【联接表】">
<key column="cuuid 【联接表里代表自己的数据库列名】"/>
<many-to-one name= "parent" column="puuid 【联接表里代表对方的数据库列名】" unique="true 【写死】"/>
</join>注解的配置
1 【tbl_parent 】:1
2@OneToMany(mappedBy="parent 【对方的Java类属性名】")
private Set<ChildModel> children = new HashSet<ChildModel>();多 【tbl_child】:
1
2
3
4
5
6
7@ManyToOne
@JoinTable(
name="tbl_parent_child 【联接表】",
joinColumns=@JoinColumn(name="cuuid 【联接表里代表自己的数据库字段名】"),
inverseJoinColumns=@JoinColumn(name="puuid 【联接表里代表对方的数据库字段名】")
)
private ParentModel parent;
关联关系映射—1:1—联接表
标准的1:M
1 | +-----------+ +-----------------------+ +----------------+ |
XML的配置
1 【tbl_product 】:1
2
3
4<join table="tbl_product_relation 【联接表】">
<key column="puuid 【联接表里代表自己的列名】"/>
<many-to-one name="course 【自己的Java属性名】" column="cuuid 【联接表里代表对方的列名】" unique="true 【写死】"/>
</join>注解的配置
1 【tbl_product 】:1
2
3
4
5
6
7@ManyToOne
@JoinTable(
name="tbl_product_relation 【联接表】",
joinColumns=@JoinColumn(name="suuid 【联接表里代表自己的列名】"),
inverseJoinColumns=@JoinColumn(name="cuuid 【联接表里代表对方的列名】",unique=true 【写死】)
)
private CourseModel course;
二级缓存
@Cache示例
定义在实体类上,示例如下:
1 | @Entity |
批量处理
可以使用循环进行批量处理。批量插入、更新时为了避免运行失败,定时将Session缓存的数据刷入数据库
1 | //累加器i是20的倍数时,将Session中的数据刷入数据库,并清空Session缓存 |
批量更新时,如果需要返回多行数据,应该使用scroll()方法,从而充分利用服务器端游标所带来的性能优势。
1 | Session session = HibernateUtil.currentSession(); |
Hibernate提供HQL语句也可以批量更新、删除。语法
1 | UPDATE | DELETE FROM? <CLASSNAME> [WHERE WHERE_CONDITIONS] |
FROM子句中,FROM关键字是可选的。
在FROM子句中只能有一个类名,该类名不能有别名。
不能再批量HQL语句中使用连接,显式或者银石都不行。但可以在WHERE子句的语法中使用子查询。
整个WHERE子句是可选的。
1 | int updateEntities = session.createQuery(hql).executeUpdate(); |
使用HQL查询
步骤
- 获取Hibernate Session对象
- 编写HQL语句
- 以HQL语句作为参数,调用Session的createQuery方法创建查询对象。
- 如果HQL语句包含参数,则调用Query的setXXX方法为参数赋值。
- 调用Query对象的list等方法返回查询结果列表(持久化实体集)
1 | Session session = HibernateUtil.currentSession(); |
执行HQL语句类似于用PreparedStatement执行SQL语句,因此HQL语句中可以使用占位符作为参数。HQL的占位符既可使用英文问好(?),这与SQL语句中的占位符一样;也可使用有名字的占位符,使用有名字的占位符时,应该在占位符名字前增加英文冒号(:)。
setXXX():方法有两个版本,分别根据参数索引赋值和根据参数名字赋值。
list(): 返回查询到的全部结果
setFirstResult(int firstResult):设置返回的结果集从第几条开始
setMaxResults(int maxResults):设置本次查询返回的结果数目
后两个方法用于对HQL查询实现分页控制
HQL语句本身是不区分大小写的。也就是说,HQL语句的关键字、函数都是不区分大小写的。但HQL语句中所使用的包名、类名、实例名、属性名都区分大小写。
from子句
1 | from Person |
建议为每个实例起别名。as关键字是可选的,为了增加可读性,建议保留。
关联和连接
两种形式关联连接:隐式和显式
隐式连接形式不使用join关键字,使用英文点号(.)来隐式连接关联实体,Hibernate底层自动进行关联查询。
1 | Person p p.myEvents. > : |
显示连接则需要使用 xxx join关键字
1 | from Person p |
可使用几种连接方式
- inner join,内连接,可简写成join。
- left outer join,左外连接,可简写成,left join
- right outer join,右外连接,可简写成,right join
- full join,全连接,不常用
还可通过with关键字来提供额外的连接条件。
1 | from Person p |
省略select关键字,返回的结果也是集合,但集合元素是被查询持久化对象、所有被关联的持久化对象所组成的数组。如上查询将会返回person、event_table表中的所有数据。
为了查询结果不重复可以使用distinct关键字
1 | select distinct p from Person p |
如果关联实体是集合如myEvents这时不可以用隐式连接,必须显式连接关联实体或组件。
1 | from Person as p |
上次的fetch关键字将导致Hibernate在初始化Person对象时,同时抓取Person关联的scores集合属性。也可以在配置文件中制定lazy="false"
fetch关键字注意:
- fetch不应该与setMaxResults()与setFirstResult()共用。因为这些操作是基于结果集的,而在预先抓取集合类时可能包含重复的数据,即无法预先知道精确的行数。
- fetch不能与独立的with条件一起使用
- 如果在一次查询中fetch多个集合,可以查询返回笛卡尔积,因此要多加注意。
- 对bag映射而言,同时join fetch多个集合时可能出现非预期结果,因此需要谨慎使用。
- full join fetch 与 right join fetch是没有任何意义的
也可以通过fetch all properties 来强制Hibernate立即抓取这些属性。
1 | from Document fetch all properties order by name |
select子句
1 | select p.name.firstName from Person as p |
select可以选择组件属性包含的属性
通常情况下,使用select子句查询的结果是集合,而集合元素是select后的实例、属性等组成的数组。
如果select后只有一项(包括持久化实例或属性),则查询得到的集合元素就是该持久化实例或属性。
如果select后有多个项,则每个集合元素就是选择出的多项组成的数组。
1 | select p.name, p from Person as p |
集合元素类似于[String,Person]结构的数组,其中第一个元素是Person实例的name属性,第二个是Person实例
将选出的属性存入一个List对象。
1 | select new list(p.name,p.address) from Person as p |
返回的集合元素是list而不是数组
也可以将选出的属性封装为对象,必须有对应的构造方法
1 | select new ClassTest(p.name,p.address) from Person as p |
还可以给选出元素命名别名
1 | select p.name as personName from Person as p |
这种用法与new map结合使用更加普遍。
1 | select new map(p.name as personName) from Person as p |
选出的集合元素是Map对象,以personName作为Map的key,实际选出的值作为Map的value
HQL查询的聚集函数
- avg:计算属性平均值
- count:统计选择对象的数量
- max:统计属性值的最大值
- min:统计属性值的最小值
- sum:计算属性值的总和
select子句还支持字符串连接符、算术运算符,以及SQL函数。也支持使用distinct和all关键字。
1 | select p.name || "" || p.address from Person as p |
多态查询
1 | from Person as p |
该查询语句不仅会查出Person的全部实例,还会查询出Person的子类。
1 | from java.lang.Object o |
该查询可以返回所有被持久化的对象。此查询无法使用order by子句对结果集排序,从而不允许对这些查询结果使用Query.scroll()
HQL查询的where子句
1 | from Cat cat where cat.mate.name like "kit%" |
如果cat.mate是集合属性,Hibernate3.2.3以后的版本不支持这种用法。
class关键字用来存取一个实例的鉴别值。嵌入where子句中的java类名,将被作为该类的鉴别值。
1 | from Cat cat where cat.class = DomesticCat |
当where子句的运算符只支持基本类型或字符串时,where子句中的属性表达式必须以基本类型或者字符串结尾,不要使用组件类型属性结尾。
1 | from Account as a where a.person.name.firstName like "dd%" |
下面的语句则是错误的
1 | from Account as a where a.person.name like "dd%" |
‘=’可以用于实例。
表达式
在where子句中允许使用的表达式包括 大多数你可以在SQL使用的表达式种类:
数学运算符
+, -, *, /二进制比较运算符
=, >=, <=, <>, !=, like逻辑运算符
and, or, notin, not in, between, is null, is not null, is empty, is not empty, member of and not member of
“简单的” case, case … when … then … else … end,和 “搜索” case, case when … then … else … end
字符串连接符…||… or concat(…,…)
current_date(), current_time(), current_timestamp()
second(…), minute(…), hour(…), day(…), month(…), year(…),
EJB-QL 3.0定义的任何函数或操作:substring(), trim(), lower(), upper(), length(), locate(), abs(), sqrt(), bit_length()
coalesce() 和 nullif()
cast(… as …), 其第二个参数是某Hibernate类型的名字,以及extract(… from …),只要ANSI cast() 和 extract() 被底层数据库支持
任何数据库支持的SQL标量函数,比如sign(), trunc(), rtrim(), sin()
JDBC参数传入 ?
命名参数:name, :start_date, :x1
SQL 直接常量 ‘foo’, 69, ‘1970-01-01 10:00:01.0’
Java public static final 类型的常量 eg.Color.TABBY
关键字in与between可按如下方法使用:
1
2from DomesticCat cat where cat.name between 'A' and 'B'
from DomesticCat cat where cat.name in ( 'Foo', 'Bar', 'Baz' )而且否定的格式也可以如下书写:
1
2from DomesticCat cat where cat.name not between 'A' and 'B'
from DomesticCat cat where cat.name not in ( 'Foo', 'Bar', 'Baz' )同样, 子句is null与is not null可以被用来测试空值(null).
在Hibernate配置文件中声明HQL“查询替代(query substitutions)”之后, 布尔表达式(Booleans)可以在其他表达式中轻松的使用:
1
<property name="hibernate.query.substitutions">true 1, false 0</property>
系统将该HQL转换为SQL语句时,该设置表明将用字符 1 和 0 来 取代关键字true 和 false:
1
from Cat cat where cat.alive = true
你可以用特殊属性size, 或是特殊函数size()测试一个集合的大小。
1
2from Cat cat where cat.kittens.size > 0
from Cat cat where size(cat.kittens) > 0对于索引了(有序)的集合,你可以使用minindex 与 maxindex函数来引用到最小与最大的索引序数。 同理,你可以使用minelement 与 maxelement函数来 引用到一个基本数据类型的集合中最小与最大的元素。
1
2
3from Calendar cal where maxelement(cal.holidays) > current date
from Order order where maxindex(order.items) > 100
from Order order where minelement(order.items) > 10000在传递一个集合的索引集或者是元素集(elements与indices 函数) 或者传递一个子查询的结果的时候,可以使用SQL函数any, some, all, exists, in
1
2
3
4
5
6
7select mother from Cat as mother, Cat as kit
where kit in elements(foo.kittens)
select p from NameList list, Person p
where p.name = some elements(list.names)
from Cat cat where exists elements(cat.kittens)
from Player p where 3 > all elements(p.scores)
from Show show where 'fizard' in indices(show.acts)注意,在Hibernate3种,这些结构变量- size, elements, indices, minindex, maxindex, minelement, maxelement - 只能在where子句中使用。
一个被索引过的(有序的)集合的元素(arrays, lists, maps)可以在其他索引中被引用(只能在where子句中):
1
2
3
4
5
6
7
8.items[0].id = 1234
person Person person, Calendar calendar
calendar.holidays['national day'] = person.birthDay
person.nationality.calendar = calendar
item Item item,
.items[ .deliveredItemIndices[0] ] = item .id = 11
item Item item,
.items[ ma.items) ] = item .id = 11在[]中的表达式甚至可以是一个算数表达式。
1
2select item from Item item, Order order
where order.items[ size(order.items) - 1 ] = item对于一个一对多的关联(one-to-many association)或是值的集合中的元素, HQL也提供内建的index()函数,
1
2
3select item, index(item) from Order order
join order.items item
where index(item) < 5如果底层数据库支持标量的SQL函数,它们也可以被使用
1
from DomesticCat cat where upper(cat.name) like 'FRI%'
如果你还不能对所有的这些深信不疑,想想下面的查询。如果使用SQL,语句长度会增长多少,可读性会下降多少:
1
2
3
4
5
6
7select cust
from Product prod,
Store store
inner join store.customers cust
where prod.name = 'widget'
and store.location.name in ( 'Melbourne', 'Sydney' )
and prod = all elements(cust.currentOrder.lineItems)提示: 会像如下的语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17SELECT cust.name, cust.address, cust.phone, cust.id, cust.current_order
FROM customers cust,
stores store,
locations loc,
store_customers sc,
product prod
WHERE prod.name = 'widget'
AND store.loc_id = loc.id
AND loc.name IN ( 'Melbourne', 'Sydney' )
AND sc.store_id = store.id
AND sc.cust_id = cust.id
AND prod.id = ALL(
SELECT item.prod_id
FROM line_items item, orders o
WHERE item.order_id = o.id
AND cust.current_order = o.id
)
order by子句
查询返回的列表(list)可以按照一个返回的类或组件(components)中的任何属性(property)进行排序:
1 | from DomesticCat cat |
可选的asc或desc关键字指明了按照升序或降序进行排序.默认是升序排序。
group by子句
一个返回聚集值(aggregate values)的查询可以按照一个返回的类或组件(components)中的任何属性(property)进行分组:
1 | select cat.color, sum(cat.weight), count(cat) |
having子句在这里也允许使用.
1 | select cat.color, sum(cat.weight), count(cat) |
如果底层的数据库支持的话(例如不能在MySQL中使用),SQL的一般函数与聚集函数也可以出现 在having与order by 子句中。
1 | select cat |
注意group by子句与 order by子句中都不能包含算术表达式(arithmetic expressions).
子查询
对于支持子查询的数据库,Hibernate支持在查询中使用子查询。一个子查询必须被圆括号包围起来(经常是SQL聚集函数的圆括号)。 甚至相互关联的子查询(引用到外部查询中的别名的子查询)也是允许的。
1 | from Cat as fatcat |
在select列表中包含一个表达式以上的子查询,你可以使用一个元组构造符(tuple constructors):
1 | from Cat as cat |
注意在某些数据库中(不包括Oracle与HSQL),你也可以在其他语境中使用元组构造符, 比如查询用户类型的组件与组合:
1 | from Person where name = ('Gavin', 'A', 'King') |
该查询等价于更复杂的:
1 | from Person where name.first = 'Gavin' and name.initial = 'A' and name.last = 'King') |
有两个很好的理由使你不应当作这样的事情:首先,它不完全适用于各个数据库平台;其次,查询现在依赖于映射文件中属性的顺序。
命名查询
命名查询实际上就是给查询语句起个名字,执行查询的时候就是直接使用起的这个名字,避免重复写HQL语句,使查询在代码中得到更多的重用。
使用@NamedQuery注解在实体类中定义命名查询。
1
@NamedQuery(name="findAllUser",query="SELECT u FROM User u")
@NamedQuery中的属性name指定命名查询的名称,query属性指定命名查询的语句。
如果要定义多个命名查询,需要使用@NamedQueries。
1
2
3
4
5@NamedQueries({
@NamedQuery(name="findAllUser",query="SELECT u FROM User u"),
@NamedQuery(name="findUserWithId",query="SELECT u FROM User u WHERE u.id = ?1"),
@NamedQuery(name="findUserWithName",query="SELECT u FROM User u WHERE u.name = :name")
})定义好命名查询后,可以使用EntityManager的createNamedQuery方法传入命名查询的名称创建查询。例如:createNamedQuery(“findAllUser”);
一个简单的例子。
1 | package entity; |
测试
1 | import java.util.List; |
条件查询
- Criteria:代表一次查询
- Criterion:代表一个查询条件
- Restrictions:产生查询条件的工具类
执行条件查询的步骤如下:
- 获得Hibernate的Session对象
- 以Session对象创建Criteria (org.hibernate.Criteria接口表示特定持久类的一个查询。Session是 Criteria实例的工厂。)
- 使用Restrictions的静态方法创建Criterion查询条件
- 向Criteria查询中添加Criterion查询条件
- 执行Criteria的list等方法返回结果集
1 | List list = session.createCriteria(Student.class) |
Criteria常用方法
- Criteria setFirstResult(int firstResult):设置查询返回的第一行记录
- Criteria setMaxResults(int maxResults):设置查询返回的记录数
- Criteria add(Criterion criterion):增加查询条件
- Criteria addOrder(Order order):增加排序规则
Restrictions产生查询条件Criterion,常用静态方法
下面方法返回Criterion
- Restrictions.eq –> equal,等于.
- Restrictions.allEq –> 参数为Map对象,使用key/value进行多个等于的比对,相当于多个Restrictions.eq的效果
- Restrictions.gt –> great-than > 大于
- Restrictions.ge –> great-equal >= 大于等于
- Restrictions.lt –> less-than, < 小于
- Restrictions.le –> less-equal <= 小于等于
- Restrictions.between –> 对应SQL的between子句
- Restrictions.like –> 对应SQL的LIKE子句
- Restrictions.in –> 对应SQL的in子句
- Restrictions.and –> and 关系
- Restrictions.or –> or 关系
- Restrictions.not –> 求否
- Restrictions.isEmpty –> 判断属性是否为空,为空则返回true
- Restrictions.isNotEmpty –> 与isNull相反
- Restrictions.isNull –> 判断属性是否为空,为空则返回true
- Restrictions.isNotNull –> 与isNull相反
- Restrictions.sqlRestriction –> SQL限定的查询
- Restrictions.sizeEq –> 判断某个属性的元素个数是否与size相等
下面方法返回Order - Restrictions.asc –> 限定升序排序
- Restrictions.desc –> 限定降序排序
关联和动态关联
你可以使用createCriteria()非常容易的在互相关联的实体间建立约束。
1 | List list = session.createCriteria(Student.class) |
第一个查询条件是直接过滤Person的属性。第二个查询条件则过滤Person的关联实体的属性,其中enrolments是Person类的关联实体,而semester则是Enrolment类的属性。返回的并不是Enrolment对象,而是Person对象的集合。
1 | List list = session.createCriteria(Student.class) |
createAlias()并不创建一个新的 Criteria实例。它只是给关联实体(包括集合里包含的关联实体)起一个别名,让后面的过滤条件可根据该关联实体进行筛选。
Student实例所保存的之前两次查询所返回的enrolments集合是没有被条件预过滤的。如果你希望只获得符合条件的enrolments, 你必须使用returnMaps()。
1 | List list = session.createCriteria(Student.class) |
动态关联抓取
FetchMode里有如下几个常量:
- DEFAULT:使用配置文件指定的延迟加载策略处理
- JOIN:使用外连接、预初始化所有关联实体
- SELECT:启用延迟加载,系统将使用单独的select语句来初始化关联实体。只有当真正访问关联实体的时候,才会执行第二条select语句。
你可以使用setFetchMode()在运行时定义动态关联抓取的语义。
1 | List list = session.createCriteria(Student.class) |
以上程序会预初始化Student关联的enrolments集合。
投影(Projections)、聚合(aggregation)和分组(grouping)
org.hibernate.criterion.Projections是 Projection 的实例工厂。我们通过调用 setProjection()应用投影到一个查询。
- AggregateProjection avg(String propertyName):类似avg函数
- CountProjection count(String propertyName):类似count函数
- CountProjection countDistinct(String propertyName):类似count(distinct column)
- PropertyProjection groupProperty(String propertyName):类似添加group by子句
- AggregateProjection max(String propertyName):类似max函数
- AggregateProjection min(String propertyName):类似min函数
- Projection rowCount():类似count(*)
- AggregateProjection sum(String propertyName):类似sum函数
1 | List results = session.createCriteria(Cat.class) |
在一个条件查询中没有必要显式的使用 “group by” 。某些投影类型就是被定义为 分组投影,他们也出现在SQL的group by子句中。
你可以选择把一个别名指派给一个投影,这样可以使投影值被约束或排序所引用。下面是两种不同的实现方式:
1 | List results = session.createCriteria(Cat.class) |
alias()和as()方法简便的将一个投影实例包装到另外一个别名的Projection实例中。简而言之,当你添加一个投影到一个投影列表中时你可以为它指定一个别名,使用ProjectionList的add()方法添加投影时指定别名
离线(detached)查询和子查询
DetachedCriteria类使你在一个session范围之外创建一个查询,并且可以使用任意的 Session来执行它。
1 | DetachedCriteria query = DetachedCriteria.forClass(Cat.class) |
DetachedCriteria也可以用以表示子查询。条件实例包含子查询可以通过 Subqueries或者Property获得。
1 | DetachedCriteria avgWeight = DetachedCriteria.forClass(Cat.class) |
甚至相互关联的子查询也是有可能的:
1 | DetachedCriteria avgWeightForSex = DetachedCriteria.forClass(Cat.class, "cat2") |
SQL查询
SQL查询是通过SQLQuery接口来表示的。Query接口的子接口,可调用Query接口的方法:setFirstResult、setMaxResults、list。
此外还有两个重载的方法。
- addEntity():将查询到的记录与特定的实体关联。
- addScalar():将查询到的记录关联成标量值。
执行SQL查询的步骤如下:
- 获取Hibernate Session对象
- 编写SQL语句
- 以SQL语句为参数,调用Session的createSQLQuery方法创建查询对象
- 调用SQLQuery对象的addScalar或addEntity方法将选出的结果与标量值或实体进行关联,分别用于进行标量查询或实体查询。
- 如果SQL语句包含参数,则调用Query的setxxx方法为参数赋值。
- 调用Query的list方法返回查询的结果集。
标量查询
1 | session.createSQLQuery("select * from student_inf") |
list方法返回数组元素的List,但是像上面程序指定了name列,只会返回单个变量值的List
addScalar的作用
- 指定查询结果包含哪些数据列–没有被addScalar选出的列将不会包含在查询结果中。
- 指定查询结果中数据列的数据类型。
实体查询
如果查询返回了某个数据表的全部数据列(记住:是选出全部数据列),且该数据表有对应的持久化类映射,我们就可把查询结果转换成实体查询。将查询结果转换成实体,可以使用addEntity方法。
1 | List list = session.createSQLQuery("select enrolment_inf where year=:year") |
可以看出原生SQL语句一样支持使用参数。
Hibernate还支持将查询结果转换成多个实体。如果要将查询结果转换成多个实体,则需要指定别名,并调用addEntity(String alias, Class entityClass)方法将不同数据表转换成不同实体。
Hibernate还可将查询的结果转换成非持久化实体,只要该JavaBean为这些数据列提供了对应的setter和getter方法。
1 | List list = session.createSQLQuery(SQLQuery).setResultTransformer(Transformers.aliasToBean(StudentCourse.class)).list(); |
处理关联和继承
将关联实体转换成查询结果的方法是SQLQuery addJoin(String alias, String path),该方法第一个参数是转换后的实体名,第二个参数是待转换的实体属性。
1 | public void joinQuery(){ |
上面的程序中可以看到的,程序将s.enrolments属性转换成别名为e的实体,也就是说程序执行的结果是Student、Enrolment对象数组的列表。
命名SQL查询
1 |
|
使用Session的getNamedQuery即可获取指定命名SQL查询。
1 | session.getNamedQuery("compositekey").list(); |
调用存储过程
Hibernate可以通过命名SQL查询来调用存储过程或函数。对于函数,该函数必须返回一个结果集;对于存储过程,该存储过程的第一个参数必须是传出参数,且数据类型是结果集。
1 | create procedure select_all_student() |
如果需要使用该存储过程,可以先将其定义成命名SQL查询,当使用原生SQL来调用存储过程或触发器时,应为<sql-query.../>元素指定callable="true"。还需要使用<return-property .../>子元素将指定列转换成实体的属性。
1 | <sql-query name="callProcedure" callable="true"> |
调用存储过程
1 | private void callProcedure(){ |
注意
- 建议采用的调用方式是标准SQL92语法,如
{?=call functionName(<parameters>)}或{callprocedureName(<parameters>)},不支持原生的调用语法。 - 因为存储过程本身完成了查询的全部操作。因此,调用存储过程进行的查询无法使用setFirstResult/setMaxResults进行分页。
对于Oracle有如下规则:
- 存储过程必须返回一个结果集.它通过返回
SYS_REFCURSOR实现(在Oracle9或10),在Oracle里你需要定义一个REF CURSOR类型 - 推荐的格式是
{ ? = call procName(<parameters>) }或{ ? = call procName }(这更像是Oracle规则而不是Hibernate规则)
对于Sybase或者MS SQL server有如下规则:
- 存储过程必须返回一个结果集。.注意这些servers可能返回多个结果集以及更新的数目.Hibernate将取出第一条结果集作为它的返回值, 其他将被丢弃。
- 如果你能够在存储过程里设定SET NOCOUNT ON,这可能会效率更高,但这不是必需的。
定制SQL
1 | @Entity |
也可以使用xml配置文件形式
1 | <class name="Person"> |
使用存储过程也是可以的,需要指定callable="true",调用存储过程的顺序必须和Hibernate所期待的顺序相同。程序将日志调试级别设为org.hibernate.persister.entity。
1 | <class name="Person"> |
数据过滤
过滤器和定义在类和集合映射文件上的where属性非常相似。它们的区别是过滤器可以带参数,应用程序可以在运行时决定是否启用指定的过滤器,使用怎样的参数值。而映射文见上的where属性将一直生效,且无法动态传入参数。
过滤器的用法很想数据库视图,区别是视图在数据库中已经定义完成,而过滤器则还需在应用程序中确定参数值。
@org.hibernate.annotations.FilterDef 或 @FilterDefs 定义过滤器声明,为同名过滤器所用. 过滤器声明带有一个name()和一个parameters()数组,@ParamDef包含name和type, 你还可以为给定的@filterDef定义一个defaultCondition()参数, 当@Filter中没有任何定义时,可使用该参数定义缺省条件. @FilterDef (s)可以在类或包一级进行定义.
现在我们来定义应用于实体或集合加载时的SQL过滤器子句.我们使用@Filter,并将其置于实体或集合元素上。
1 | @Entity |
过滤器的目标是实体表,使用@Filter,如果是关联表使用@FilterJoinTable
1 | @OneToMany |
默认情况下,Hibernate自动确定@Filter SQL条件中的所有点,这样别名需要被注入,设置@Filter中deduceAliasInjectionPoints为false。然后使用@SqlFragmentAlias注解,在SQL的条件语句中使用{alias}占位符。
1 | @Entity |
对于xml配置文件方式,系统默认不启用过滤器,必须通过Session的enableFilter(String filterName)才可以启用过滤器,该方法返回一个Filter实例,Filter包含setParameter方法用于为过滤器参数赋值。
通常来说,如果某个筛选条件使用得非常频繁,那么我们可以将该筛选条件设置为过滤器;如果是临时的数据筛选,还是使用常规查询比较好。对于在SQL语句中使用行内表达式、视图的地方,现在可考虑使用过滤器。
事物控制
事务的概念
事务是一步或几步基本操作组成的逻辑执行单元,这些基本操作作为一个整体执行单元,它们要么全部执行,要么全部取消,绝不能仅仅执行部分。一般而言,每次用户请求,对应一个业务逻辑方法,一个业务逻辑方法往往具有逻辑上的原子性,应该使用事务。
事务具备4个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这四个特性简称ACID性。
Session与事务
Hibernate的事务(Transaction对象)通过Session的beginTransaction方法显式打开,Hibernate自身并不提供事务控制行为,底层直接使用JDBC连接、JTA资源或其他资源的事务。
从编程角度来看,Hibernate的事务由Session对象开启;从底层实现来看,Hibernate事务由TransactionFactory的实例来产生。
TransactionFactory是一个事务工厂的接口,有不同实现:CMTTransactionFactory(针对容器管理事务环境的实现类)、JDBCTransactionFactory(针对JDBC局部事务环境的实现类)、JTATransactionFactory(针对JTA全局事务环境的实现类)。
SessionFactory底层封装了TransactionFactory。SessionFactory创建的代价很高,它是线程安全的对象,被设计成可以被所有线程所共享。通常,SessionFactory会在应用启动时创建,一旦创建将不会轻易关闭,只有退出时才关闭。
Session是轻量级的,是线程不安全的。对于单个业务进程、单个的工作单元而言,Session只被使用一次。创建Session时,并不会立即打开与数据库之间的连接,只有需要进行数据库操作时,Session才会获取JDBC连接。因此,打开和关闭Session,并不会对性能造成很大影响。甚至即使无法确定一个请求是否需要数据访问,也可以打开Session对象,因为如果不进行数据库访问,Session不会获取JDBC连接。
数据库事务应该尽可能短,降低数据库锁定造成的资源争用。
Hibernate的所有持久化访问都必须在Session管理下进行,但并不推荐因为一次简单的数据库原子操作,就打开和关闭一次Session,数据库事务也是如此。
Hibernate建议采用每个请求对应一次Session的模式–因此一次请求通常表示需要执行一个完整的业务功能,这个功能由系列的数据库原子操作组成,而且它们应该是一个逻辑上的整体。
对于长事务,Hibernate有如下三种模式:
- 自动版本化 - Hibernate能够自动进行乐观并发控制,如果在用户思考的过程中发生并发修改冲突,Hibernate能够自动检测到。
- 脱管对象(Detached Objects)- 如果你决定采用前面已经讨论过的 session-per-request模式,所有载入的实例在用户思考的过程中都处于与Session脱离的状态。Hibernate允许你把与Session脱离的对象重新关联到Session上,并且对修改进行持久化,这种模式被称为 session-per-request-with-detached-objects。自动版本化被用来隔离并发修改。
- 长生命周期的Session (Long Session)- Hibernate 的Session 可以在数据库事务提交之后和底层的JDBC连接断开,当一个新的客户端请求到来的时候,它又重新连接上底层的 JDBC连接。这种模式被称之为session-per-application-transaction,这种情况可 能会造成不必要的Session和JDBC连接的重新关联。自动版本化被用来隔离并发修改。
如果程序打开Session很长时间,或载入过多数据,Session占用的内存会一直增长,直到抛出OutOfMemoryException。可以通过clear和evict方法管理Session的缓存。对于大批量的数据处理,推荐使用DML风格 的HQL语句完成。
如果在Session范围之外,访问未初始化的集合或代理(由Hibernate的延迟加载特性所引起),HIbernate将会抛出LazyInitializationException异常。
Hibernate的initialize静态方法可以强制初始化某个集合或代理。只要Session处于open状态,Hibernate.initialize(teacher)将会初始化teacher代理。
两种方法保证Session处于打开状态:
- 在一个Web应用中,可以利用过滤器,在用户请求结束、页面生成结束时关闭Session。也就是保证视图显示层一直打开Session,这就是所谓的Open Session in View模式。当然采用这种模式时必须保证所有异常得到正确处理,在呈现视图界面之前,或在生成视图界面的过程中发生异常时,必须保证可以正确关闭Session,并结束事务。(Spring框架提供的OpenSessionInViewFilter就可以满足这个要求。
- 使用业务逻辑层负责准备数据,在业务逻辑层返回数据之前,业务逻辑层对每个所需集合调用Hibernate.initialize()方法,或者使用带fetch子句或FetchMode.JOIN的查询,事先取得所有数据,并将这些数据封装成VO(值对象)集合,然后程序可以关闭Session了。业务逻辑层将VO集传入视图层,让视图层只负责简单的显示逻辑。这种模式下,可以让视图层和Hibernate API彻底分离,保证视图层不会出现持久层API。
上下文相关的会话
从 3.1 开始,SessionFactory.getCurrentSession() 的后台实现是可拔插的。因此,我们引入了新的扩展接口(org.hibernate.context.CurrentSessionContext)和新的配置参数(hibernate.current_session_context_class),以便对什么是当前会话的范围(scope)和上下文(context)的定义进行拔插。
Hibernate 内置了org.hibernate.context.CurrentSessionContext 接口的三种实现:
- org.hibernate.context.JTASessionContext:当前会话根据 JTA 来跟踪和界定。这和以前的仅支持 JTA 的方法是完全一样的。详情请参阅 Javadoc。
- org.hibernate.context.ThreadLocalSessionContext:当前会话通过当前执行的线程来跟踪和界定。详情也请参阅 Javadoc。
- org.hibernate.context.ManagedSessionContext:当前会话通过当前执行的线程来跟踪和界定。但是,你需要负责使用这个类的静态方法将 Session 实例绑定、或者取消绑定,它并不会打开(open)、flush 或者关闭(close)任何 Session。
对于在容器中使用Hibernate的场景而言,通常会采用第一种方式;对于独立的Hibernate应用而言,通常会采用第二种方式。
在hibernate.cfg.xml文件中增加以下中的一种配置
1 | <property name="hibernate.current_session_context_class">thread</property> |
二级缓存和查询缓存
Hibernate 两个级别的缓存
- 默认总是启用的Session级别的一级缓存
- 可选的SessionFactory级别的二级缓存
其中Session级别的一级缓存不需要开发者关心,默认总是有效的,当应用保存持久化实体、修改持久化实体时,Session并不会立即把这种改变flush到数据库,而是缓存在当前Session的一级缓存中,除非程序显式调用Session的flush方法,或程序关闭Session时才会把这些改变一次性flush到底层数据库。
SessionFactory级别的二级缓存是全局性的,应用的所有Session都共享这个二级缓存。不过此级别的缓存默认是关闭的,必须由程序显式开启。Session优先从二级缓存抓取数据。
开启二级缓存
1 | <!--开启二级缓存--> |
缓存策略提供商(Cache Providers)
| Cache | Provider class | Type | Cluster Safe | Query Cache Supported |
|---|---|---|---|---|
| Hashtable | org.hibernate.cache.HashtableCacheProvider | memory | yes | |
| EHCache | org.hibernate.cache.EhCacheProvider | memory, disk | yes | |
| OSCache | org.hibernate.cache.OSCacheProvider | memory, disk | yes | |
| SwarmCache | org.hibernate.cache.SwarmCacheProvider | clustered (ip multicast) | yes (clustered invalidation) | |
| JBoss Cache 1.x | org.hibernate.cache.TreeCacheProvider | clustered (ip multicast), transactional | yes (replication) | yes (clock sync req.) |
| JBoss Cache 2 | org.hibernate.cache.jbc.JBossCacheRegionFactory | clustered (ip multicast), transactional | yes (replication) | yes (clock sync req.) |
EHCache缓存配置文件ehcache.xml,将其放在类加载路径下稍作修改即可。
1 |
|
@org.hibernate.annotations.Cache定义了缓存策略及给定的二级缓存的范围. 此注解适用于根实体(非子实体),还有集合.
1 | @Entity |
1 | @Cache( |
(1) usage: 给定缓存的并发策略(NONE, READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, TRANSACTIONAL)
(2) region (可选的):缓存范围(默认为类的全限定类名或是集合的全限定角色名)
(3) include (可选的):值为all时包括了所有的属性(proterty), 为non-lazy时仅含非延迟属性(默认值为all)
- 只读策略缓存(Strategy: read only)
如果你的应用程序只需读取一个持久化类的实例,而无需对其修改, 那么就可以对其进行只读 缓存。这是最简单,也是实用性最好的方法。甚至在集群中,它也能完美地运作。 - 读/写策略(Strategy: read/write)
如果应用程序需要更新数据,那么使用读/写缓存 比较合适。 如果应用程序要求“序列化事务”的隔离级别(serializable transaction isolation level),那么就决不能使用这种缓存策略。 如果在JTA环境中使用缓存,你必须指定hibernate.transaction.manager_lookup_class属性的值, 通过它,Hibernate才能知道该应用程序中JTA的TransactionManager的具体策略。 在其它环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。 如果你想在集群环境中使用此策略,你必须保证底层的缓存实现支持锁定(locking)。Hibernate内置的缓存策略并不支持锁定功能。 - 非严格读/写策略(Strategy: nonstrict read/write)
如果应用程序只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情况很不常见),也不需要十分严格的事务隔离, 那么比较适合使用非严格读/写缓存策略。如果在JTA环境中使用该策略, 你必须为其指定hibernate.transaction.manager_lookup_class属性的值, 在其它环境中,你必须保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束。 - 事务策略(transactional)
Hibernate的事务缓存策略提供了全事务的缓存支持, 例如对JBoss TreeCache的支持。这样的缓存只能用于JTA环境中,你必须指定 为其hibernate.transaction.manager_lookup_class属性。
管理缓存和统计缓存
无论何时,当你给save()、update()或 saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。
当随后flush()方法被调用时,对象的状态会和数据库取得同步。 如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合。
1 | News news = (News) newsList.get(0); |
Session还提供了一个contains()方法,用来判断某个实例是否处于当前session的缓存中。
如若要把所有的对象从session缓存中彻底清除,则需要调用Session.clear()。
对于二级缓存来说,在SessionFactory中定义了许多方法, 清除缓存中实例、整个类、集合实例或者整个集合。
1 | sessionFactory.evict(Cat.class, catId); //evict a particular Cat |
如若需要查看二级缓存或查询缓存区域的内容,你可以使用统计(Statistics) API。
此时,你必须手工打开统计选项。可选的,你可以让Hibernate更人工可读的方式维护缓存内容。
1 | <!-- 开启二级缓存的统计功能 --> |
1 | Map cacheEntries = sessionFactory.getStatistics() |
使用查询缓存
大部分情况下查询缓存并不能提供应用性能,甚至反而会降低应用性能,因此实际项目中慎重使用查询缓存。
首先在配置文件中增加如下配置
1 | <!-- 启用查询缓存 --> |
此外还需要调用Query对象的setCacheable(true)才会对查询结果进行缓存。
事件机制
Hibernate的事件框架由两个部分组成
- 拦截器机制:对于特定动作拦截,回调应用中的特定动作。
- 事件系统:重写Hibernate的事件监听器。
拦截器
Interceptor接口提供了从会话(session)回调(callback)应用程序(application)的机制,这种回调机制可以允许应用程序在持久化对象被保存、更新、删除或是加载之前,检查并(或)修改其属性。一个可能的用途,就是用来跟踪审核(auditing)信息。
创建会话(session)的时候可以指定拦截器。
1
Session session = sf.openSession( new MyInterceptor() );
也可以使用Configuration来设置一个全局范围的拦截器。
1
new Configuration().setInterceptor( new MyInterceptor() );
事件系统
基本上,Session接口的每个方法都有相对应的事件。比如 LoadEvent,FlushEvent,等等(查阅XML配置文件 的DTD,以及org.hibernate.event包来获得所有已定义的事件的列表)。当某个方法被调用时,Hibernate Session会生成一个相对应的事件并激活所有配置好的事件监听器。系统预设的监听器实现的处理过程就是被监听的方法要做的(被监听的方法所做的其实仅仅是激活监听器,“实际”的工作是由监听器完成的)。不过,你可以自由地选择实现一个自己定制的监听器(比如,实现并注册用来处理处理LoadEvent的LoadEventListener接口),来负责处理所有的调用Session的load()方法的请求。
监听器应该被看作是单例(singleton)对象,也就是说,所有同类型的事件的处理共享同一个监听器实例,因此监听器不应该保存任何状态(也就是不应该使用成员变量)。
用户定制的监听器应该实现与所要处理的事件相对应的接口,或者从一个合适的基类继承(甚至是从Hibernate自带的默认事件监听器类继承,为了方便你这样做,这些类都被声明成non-final的了)。用户定制的监听器可以通过编程使用Configuration对象来注册,也可以在Hibernate的XML格式的配置文件中进行声明(不支持在Properties格式的配置文件声明监听器)。下面是一个用户定制的加载事件(load event)的监听器:
1 | public class MyLoadListener extends DefaultLoadEventListener { |
你还需要修改一处配置,来告诉Hibernate以使用选定的监听器来替代默认的监听器。
1 | <hibernate-configuration> |
一个事件配置多个监听器
1 | <event type="load"> |
看看用另一种方式,通过编程的方式来注册它。
1 | Configuration cfg = new Configuration(); |
或
1 | Configuration cfg = new Configuration(); |
注册多个事件
1 | LoadEventListener[] stack = { new MyLoadListener(), new DefaultLoadEventListener()}; |
通过在XML配置文件声明而注册的监听器不能共享实例。如果在多个
为什么我们实现了特定监听器的接口,在注册的时候还要明确指出我们要注册哪个事件的监听器呢? 这是因为一个类可能实现多个监听器的接口。在注册的时候明确指定要监听的事件,可以让启用或者禁用对某个事件的监听的配置工作简单些。
参考:
基于按annotation的hibernate主键生成策略
Hibernate Annotations
JPA的查询语言—JPQL的命名查询@NamedQuery