Contents
持有对象
基本概念
容器类类库的用途是“保存对象”,可划分为两个不同概念:
Collection。一个独立元素的序列,这些元素都服从一条或多条规则。
- List必须按照插入顺序保存元素。
- Set不能有重复元素
- Queue按照排队规则来确定对象产生的顺序(通常与它们被插入的顺序相同)
Map。一组成对的“键值对”对象,允许你使用键来查找值。也被称为”关联数组”或”字典”。某种意义上来说,ArrayList也是一种Map
理想情况下,编写的大部分代码都是在与这些接口打交道,并且唯一需要指定所使用的精确类型的地方就是在创建的时候。可以这样创建一个List:List<Apple> apples = new ArrayList<Apple>好处在于修改实现时,只需要在创建处修改代码。如把ArrayList改为LinkedList。但是导出类一般具有额外的功能,如果需要使用这些功能,就不能将它们向上转型为更通用的接口。
添加一组元素
- Arrays.asList()。
public static <T> List<T> asList(T... a)该方法接受一个数组或是一个用逗号分割的元素列表(使用可变参数),并将其转换为一个List对象,然后将其返回。可以直接使用此方法的输出当做一个List,但是在这种情况下,其底层表示是数组,因此不能调整大小,如果试图用add()或delete()方法在这种列表中添加或删除元素,有可能会引发改变数组尺寸的尝试,获得“Unsupported Operation”错误。
另一个限制:会对所产生的List的类型做出最理想的假设,而不关心对它赋予的类型。 例:解决办法:使用显式类型参数说明(java 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//: holding/AsListInference.java
// Arrays.asList() makes its best guess about type.
import java.util.*;
class Snow {}
class Powder extends Snow {}
class Light extends Powder {}
class Heavy extends Powder {}
class Crusty extends Snow {}
class Slush extends Snow {}
public class AsListInference {
public static void main(String[] args) {
List<Snow> snow1 = Arrays.asList(
new Crusty(), new Slush(), new Powder());
// Won't compile:
// List<Snow> snow2 = Arrays.asList(
// new Light(), new Heavy());
// Compiler says:
// found : java.util.List<Powder>
// required: java.util.List<Snow>
// Collections.addAll() doesn't get confused:
List<Snow> snow3 = new ArrayList<Snow>();
Collections.addAll(snow3, new Light(), new Heavy());
// Give a hint using an
// explicit type argument specification:
List<Snow> snow4 = Arrays.<Snow>asList(
new Light(), new Heavy());
}
} ///:~List<Snow> snow4 = Arrays.<Snow>asList(new Light(), new Heavy());) ,象上面的例子中最后所做的那样。 - Collections.addAll()。
public static <T> boolean addAll(Collection<? super T> c, T... elements)该方法接受一个Collection对象,以及一个数组或是一个用逗号分割的列表,将元素添加到Collection中。先构建一个不包含元素的Collection,然后调用Collections.addAll()这种方式很方便,因此是首选方式。 - Collection导出类构造器,可以接受另一个Collection,用它来将自身初始化。
- Collection的addAll()方法,将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。相比使用构造函数初始化,这种方法快的多。
List
| 类 | 随机访问元素 | 插入和移除元素 | 其它 |
|---|---|---|---|
| ArrayList | 快 | 慢 | |
| LinkedList | 慢 | 快 | 更大的特性集 |
常用方法:
| 方法 | 说明 |
|---|---|
| boolean add(E e) | 向列表的尾部添加指定的元素(可选操作)。 |
| void add(int index, E element) | 在列表的指定位置插入指定元素(可选操作)。 |
| boolean addAll(Collection<? extends E> c) | 添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序(可选操作)。 |
| boolean addAll(int index, Collection<? extends E> c) | 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)。 |
| void clear() | 从列表中移除所有元素(可选操作)。 |
| boolean contains(Object o) | 如果列表包含指定的元素,则返回 true。 |
| boolean containsAll(Collection<?> c) | 如果列表包含指定 collection 的所有元素,则返回 true。 |
| boolean equals(Object o) | 比较指定的对象与列表是否相等。 |
| E get(int index) | 返回列表中指定位置的元素。 |
| int hashCode() | 返回列表的哈希码值。 |
| int indexOf(Object o) | 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。 |
| boolean isEmpty() | 如果列表不包含元素,则返回 true。 |
| Iterator |
返回按适当顺序在列表的元素上进行迭代的迭代器。 |
| int lastIndexOf(Object o) | 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。 |
| ListIterator |
返回此列表元素的列表迭代器(按适当顺序)。 |
| ListIterator |
返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始。 |
| E remove(int index) | 移除列表中指定位置的元素(可选操作)。 |
| boolean remove(Object o) | 从此列表中移除第一次出现的指定元素(如果存在)(可选操作)。 |
| boolean removeAll(Collection<?> c) | 从列表中移除指定 collection 中包含的其所有元素(可选操作)。 |
| boolean retainAll(Collection<?> c) | 仅在列表中保留指定 collection 中所包含的元素(可选操作)。交集 |
| E set(int index, E element) | 用指定元素替换列表中指定位置的元素(可选操作)。 |
| int size() | 返回列表中的元素数。 |
| List |
返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。 |
| Object[] toArray() | 返回按适当顺序包含列表中的所有元素的数组(从第一个元素到最后一个元素)。 |
| 返回按适当顺序(从第一个元素到最后一个元素)包含列表中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 |
- contains()、remove()、retainAll()、removeAll()方法都是基于equals()方法的。不同类,equals()方法定义可能有所不同,比如String只有在内容完全一样的情况下才会是等价的。
- subList()返回的列表的修改都会反映到初始列表中,反之亦然。
- Collections.sort(),Collections.shuffle()方法,进行排序、打乱顺序。
- List重载了一个addAll(int, Collection)方法,可以插入一个新的列表到List中间; Collection的addAll方法追加到结尾。
- toArray()方法:有一个重载;无参数的返回Object[];传递目标类型的数组,将返回指定类型的数组,传递的数组如果太小,该方法新创建一个合适尺寸的数组。
容器的打印
数组需要用Arrays.toString(),容器不需要任何其它手段 (它们的toString()方法就足够了)。
Collection打印出来的内容以[]括住,逗号分隔;Map则用{},逗号分隔,键和值用=连接。
HashSet(HashMap)提供最快的查找技术,存储顺序无实际意义;LinkedHashSet(LinkedHashMap)按照被插入的顺序保存元素;TreeSet(TreeMap)按照比较结果的升序保存对象。
迭代器
一种设计模式,在不知道或不关心序列底层结构的情况下,遍历序列,选择每一个元素。迭代器是一种轻量级对象:创建代价低。
Java的Iterator只能单向移动,用法:
- 使用iterator()方法返回Collection的迭代器;迭代器准备返回序列的第一个元素;
- 使用next()方法获取下一个元素;
注意:iterator()返回的迭代器是”准备返回序列的第一个元素”,而不是已经指向了第一个元素,因此要获取第一个元素也得调用一次next(),即c.iterator().next()得到的是第一个元素。 - hasNext()方法检验序列是否还有元素;
- 使用remove()方法删除迭代器返回的最后一个元素。注意,remove()是一种可选方法,依赖于具体实现,但Java标准容器类库都实现了这个方法。
当仅仅是遍历并获取每个元素,用foreach语法更简练。调用remove()之前必须调用next()方法。注意ConcurrentModificationException异常(所谓的fail-fast iterator)。
迭代器的威力:将遍历序列的操作与序列的底层结构分离,统一了对容器的访问方式。
ListIterator:Iterator的子类,只能用于List类的访问,可双向移动;可以返回前一个和后一个元素的索引;可以使用set()方法替换最后访问的元素;listIterator()方法返回指向List开始处的ListIterator;listIterator(n)方法返回指向索引为n的元素处的ListIterator。
LinkedList
LinkedList添加了一些可以使其用于栈、队列或双端队列的方法。
某些方法只是别名,或者只存在些许差异,以使得它们在特定用法的上下文环境中更加适用(特别是在Queue中)。
- getFirst()和element()方法完全相同,都返回列表的头,而并不移除它,如果List为空,抛出NoSuchElementException;peek()方法与他们基本相同,只是列表为空时返回null。
- removeFirst()与remove()方法相同,移除并返回列表的头,List为空,抛出NoSuchElementException;poll()方法只是在列表为空时返回null。
- offer()、add()、addLast()相同,都将某个元素插入到列表的尾端。
- addFirst()将元素插入到列表的头。
- removeLast()移除并返回列表的最后一个元素。
Stack
java.util中的Stack类采用了继承LinkedList的方式实现,实际上使用组合实现更好。
Set
查找是Set最重要的操作,因此通常选择HashSet,因为快速查找正是它的长项。
Set的接口与Collection接口完全相同,只是行为不同而已,典型的继承与多态。
TreeSet使用红黑树数据结构,HashSet使用散列函数来保存对象,LinkedHashSet也使用散列来优化查找速度,但看起来使用链表来维护元素的插入顺序。
TreeSet默认按照字典序(lexicographically)排序,如果需要改变排序方法,可将比较器传给TreeSet构造器,如String.CASE_INSENTIVE_ORDER(按照字母表顺序alphabetically)。
Map
get(key)返回key所对应的值,如果key不在Map中,返回null。
containKey()和containValue()方法。
多维Map:值为Map或者别的Array、Collections。
Map可以返回它的键的Set(keySet()方法),它的值的Collection(values()方法),或者它的键值对的Set(entrySet())。
Queue
Queue常被用来可靠、安全地传输对象, 如从程序的一个区域传输到另一个区域,或者并行编程中从一个任务传输给另一个任务。
LinkedList实现了Queue接口,因此可用作Queue的一种实现(向上转型为Queue) 。
PriorityQueue
队列规则:给定一组队列中的元素,确定下一个弹出队列的元素的规则 。FIFO是典型的一种规则,声明的是下一个元素应该是等待时间最长的元素。
优先级队列:下一个元素是最需要的元素(优先级最高的元素)。 Java SE5添加了这种队列。
offer()插入一个对象到PriorityQueue时,会在队列中被排序 (实际上依赖于具体实现,典型的是插入时排序,但也可以在移除时选择最重要的元素,如果对象的优先级在队列等待时可以改变,那算法的选择就很重要)。默认排序使用对象的自然顺序,但可以通过提供Comparator(如Collections.reverseOrder(),Java SE5)改变这个顺序。peek()、poll()和remove()可以获得优先级最高的元素 (对于内置类型,最小值拥有最高优先级)。
如果要在PriorityQueue使用自定义类型,就需要添加额外的功能以提供自然顺序,或者提供自己的Comparator。
Collection和Iterator
Collection被认为是一个“附属接口”即因为要表示其它若干个接口的共性而出现的接口。
通过针对接口而非具体实现编写代码,我们的代码可以应用于更多的对象类型。
实现Collection接口可以通过继承AbstractCollection,但必须实现Iterator()和size();如果类继承自其它类,就必须实现完整的Collection,但此时实现Iterator()似乎是一种更明智的选择 ,因为生成Iterator是将队列与使用队列的方法连接在一起耦合度最小的方式,并且与实现Collection相比,在序列类上所施加的约束也少得多。
foreach与迭代器
foreach可以用于数组,也可以用于Collection对象。因为Collection对象实现了Iterable接口(Java SE5引入,包含一个产生Iterator的iterator()方法)。也就是说,foreach可以用于数组和实现了Iterable接口的类(数组并不是Iterable) 。
当类需要提供多种在foreach语句使用的方法时,可以采用适配器方法的惯用法。当已经拥有一个接口并需要另一个接口时,就可以编写适配器。例如,想在默认前向迭代器的基础上,添加产生反向迭代器的能力,此时不能使用覆盖,而是应该添加一个能够产生Iterable对象的方法,该对象可以用于foreach语句,像这样
1 | import java.util.*; |
通过这种方法,可以创建不同行为多个迭代器,如随机访问random()等。
意识到Arrays.asList()产生的List对象会使用底层数组作为其物理实现是很重要的。下面的代码直接使用Arrays.asList()返回的List,Collections.shuffle(stringList);原来的数组也会改变。
1 | class TestArrays{ |
新程序中不应该使用过时的Vector、Hashtable和Stack。
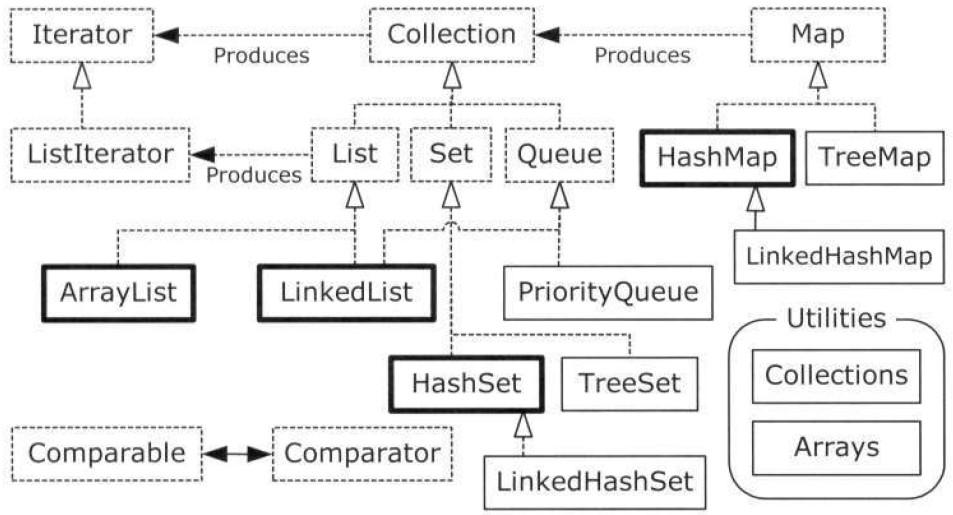
点线框表示接口,实线框表示普通的(具体的)类。带有空心箭头的点线表示一个特定的类实现了一个接口,实心箭头表示某各类可以生成箭头所指向的对象。
容器扩展:第十七章 容器深入研究
通过异常处理错误
概念
通过异常处理错误,往往可以降低错误处理代码的复杂度。可以在多处抛出异常,而只在一个地方进行处理,不仅节省代码,而且把“描述在正常执行过程中做什么事”的代码和“出了问题怎么办”的代码相分离。
基本异常
异常情形是指组织当前方法或作用域继续执行的问题。把异常情形与普通问题相区分很重要,所谓的普通问题是指,在当前环境下能够得到足够的信息,总能处理这个错误。而对于异常情形,就不能继续下去了,因为在当前环境下无法获得必要的信息来解决问题。你所能做的就是从当前环境跳出,并且把问题提交给上一级环境。这就是抛出异常时所发生的事情。
当异常抛出时,有几件事会随之发生。首先,同Java中其他对象的创建一样,将使用new在堆上创建异常对象。然后,当前的执行路径(它不能继续执行下去了)被终止,并且从当前环境中弹出对异常对象的引用。此时,异常处理机制接管程序,并开始寻找一个恰当的地方来继续执行程序。这个恰当的地方就是异常处理程序,它的任务就是将程序从错误状态中恢复,以使程序能要么换一种方式运行,要么继续运行下去。
如果程序的某部分失败了,异常将”恢复“到程序中某个已知的稳定点上。
异常参数
所有标准异常类都有两个构造器;一个是默认构造器;另一个是接受字符串作为参数,以便能把相关信息放入异常对象构造器。Throwable对象,是异常类型的根类。错误信息可以保存在异常对象内部或者用异常的名称来暗示。
捕获异常
要明白异常是如何被捕获的,必须首先理解监控区域的概念。它是一段可能产生异常的代码,并且后面跟着处理这些异常的代码。
异常处理程序
异常处理程序紧跟在try块之后,以关键字catch表示。每个catch子句看起来就像是接收一个且仅接受一个特殊类型的参数的方法。可以在处理程序内部使用标识符,这与方法参数的使用很相似。
异常处理程序必须紧跟在try块之后。当异常被抛出时,异常处理机制将负责搜索寻找参数与异常类型相匹配的第一个处理程序。
终止与恢复
异常处理理论上有两种基本模型。Java支持终止模型(它是Java和C++所支持的模型)。在这种模型中,将假设错误非常关键,一旦异常被抛出,就表明错误已经无法挽回,也不能回来继续执行。
另一种称为恢复模型。意思是在异常处理程序的工作是修正错误,然后重新尝试调用出问题的方法,并认为第二次能成功。如果想要用Java实现类似的恢复行为,那么在遇见错误时就不能抛出异常,而是调用方法来修正该错误。或者,把try块放在while循环里,这样就不断地进入try快,直到得到满意的结果。
虽然恢复模型开始显得很吸引人,但不是很实用。其中的主要原因可能是它所导致的耦合,恢复性的处理程序需要了解异常抛出地点,这势必要包含依赖于抛出未知的非通用性代码。这增加了代码编写和维护的困难。
创建自定义异常
要自己定义异常类,必须从已有的异常类继承,最好是选择意思相近的异常类继承(不过这样的异常并不容易找)。建立新的异常类型最简单的方法就是让编译器为你产生默认构造器,所以这几乎不用写多少代码。异常的名称应该可以望文生义。
异常与记录日志
可以使用java.util.logging工具将输出记录到日志中。这是一种很好的做法。
异常说明
异常说明,它属于方法声明的一部分,紧跟在形式参数列表之后。代码必须与异常说明一致。如果方法里的代码产生了异常却没有处理,编译器会发现这个问题并提醒你:要么处理异常,要么就在异常说明中表明此方法产生异常。通过这种自顶向下强制执行的异常说明机制,Java在编译时就可以保证一定水平的异常正确性。
不过还是有个能”作弊“的地方:可以声明方法抛出异常,实际上却不抛出。编译器相信了这个声明,并强制此方法的用户像真的抛出异常那样使用这个方法。这样做的好处是,为异常先占个位子,以后就可以抛出这种异常而不用修改已有的代码。在定义抽象基类和接口时,这种能力很重要,这样派生类或接口实现就能够抛出这些预先声明的异常。这种在编译时被强制检查的异常称为被检查的异常。
捕获所有异常
通过捕获异常类型的基类Exception来捕获所有类型的异常,这种捕获所有异常的代码,最好把它放在处理程序列表的末尾,以防止它抢在其他处理程序之前先把异常捕获了。
栈轨迹
printStackTrace()方法所提供的信息可以通过getStackTrace()方法来直接访问,这个方法将返回一个由栈轨迹中的元素所构成的数组,其中每一个元素都表示栈中的一帧。元素0是栈顶元素,并且是调用序列中最后一个方法调用(这个Throwable被创建和抛出之处)。
重新抛出异常
有时希望把刚捕获的异常重新抛出,尤其是在使用Exception捕获所有异常的时候。重新抛出异常会把异常抛给上一级环境中的异常处理程序,同一个try块后续catch子句将被忽略此外,异常对象的所有信息都得以保持,所以高一级环境中捕获此异常的处理程序可以从这个异常对象中得到所有信息。
如果只是把当前对象重新抛出,那么printStackTrace()方法将显示原来异常抛出点的调用信息,而并非重新抛出点的信息。想要更新这个信息,可以调用fillInStackTrack()方法,这将返回一个Throwable对象,他是通过把当前调用栈信息填入原来那个异常对象而建立的。
有可能在捕获异常之后抛出另一种异常。这么做的话,得到的效果类似于使用fillInStackTrace(),有关原来异常发生点的信息会丢失,剩下的是新的抛出点有关的信息。
异常链
常常会想要在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来,这被称为异常链。所有Throwable的子类在构造器中都可以接受一个cause对象作为参数。这个cause就用来表示原始异常,这样通过把原始异常传递给新的异常,就使得即使在当前位置创建并抛出新的异常,也能通过这个异常链追踪到异常最初发生的位置。在Throwable的子类中,只有三种基本的异常类提供了带cause参数的构造器。它们是Error,Exception和RuntimeException。如果要把其他类型的异常链接起来,应该使用initCause()方法而不是构造器。
Java标准异常
Throwable这个Java类被用来表示任何可以作为异常被抛出的类。Throwable对象可分为两种类型(指从Throwable继承而得到的类型):Error用来表示编译时和系统错误(除特殊情况外,一般不用你关心);Exception是可以被抛出的基本类型,在Java类库、用户方法以及运行时故障中都可以抛出Exception型异常。
特例:RuntimeException
RuntimeException是Java的标准运行时检测的一部分。它们会被Java虚拟机抛出,所以不必在异常说明中把它们列出来。它们被称为“不受检查异常”。这种异常属于错误,将被自动捕获。
注意,只能在代码中忽略RuntimeException(及其子类)类型的异常,其他类型异常的处理都是由编译器强制实施的。究其原因,RuntimeException代表的是编程错误。
- 无法预料的错误
- 作为程序员,应该在代码中进行检查的错误
使用finally进行清理
对于一些代码,可能会希望无论try块中的异常是否抛出,它们都能得到执行。这通常适用于内存回收之外的情况(因为回收由垃圾回收器完成)。为了达到这个效果,可以在异常处理程序后面加上finally子句。
finally用来做什么
当要把除内存之外的资源恢复到他们的初始状态时,就要用到finally子句。这种需要清理的资源包括:已经打开的文件或网络连接,在屏幕上画的图形,甚至可以是外部世界的某个开关。
在return中使用finally
因为finally子句总是会执行的,所以在一个方法中,可以从多个点返回,并且可以保证重要的清理工作仍旧会执行。无论在哪里return,finally都总是会执行。
1 | try { |
缺憾:异常丢失
遗憾的是,Java的异常实现也有瑕疵。异常作为程序出错的标志,绝不应该被忽略,但它还是有可能被轻易地忽略。用某些特殊的方式使用finally子句,就会发生这种情况。
1 | try{ |
异常的限制
当覆盖方法的时候,只能抛出在基类方法的异常说明里列出的那些异常(可以不抛出异常,但是如果抛出,必须是基类方法的声明的异常)。这个限制很有用,因为这意味着,当基类使用的代码应用到派生类对象的时候,一样能够工作(当然,这是面向对象的基本概念),异常也不例外。异常限制对构造器不起作用。派生类构造器的异常说明必须包含基类构造器的异常说明(应该是必须包含基类默认构造器的异常说明,因为基类默认构造器会被默认调用,如果显示的调用其它基类构造器,就需要声明调用的基类构造器的异常了)。派生类构造器不能捕获基类构造器的异常(不能通过try-catch捕获基类抛出的异常,必须使用异常声明)。
构造器
有一点很重要,即你要时刻询问自己“如果异常发生了,所有东西能被正确的清理吗“?尽管大多数情况下是非常安全的,但涉及构造器时,问题就出现了。构造器会把对象设置成安全的初始状态,但还会有别的动作,比如打开一个文件,这样的动作只有在对象使用完毕并且用户调用了特殊的清理方法之后才能得以清理。如果在构造器内抛出了异常,这清理行为也许就不能正常工作。这意味着在编写构造器是要格外的小心。
读者也许会认为使用finally就可以解决问题。但问题并非如此简单,因为finally会每次都执行清理代码。如果构造器在执行过程中半途而废,也许该对象的某些部分还没有被成功创建,而这些部分在finally子句中确是要被清理的。
对于在构造阶段可能会抛出异常,并且要求清理的类,最安全的使用方式是使用嵌套的try。这种通用的清理习惯在构造器不抛出任何异常时也应该运用,其基本规则是:在创建需要清理的对象之后,立即进入一个try-finally语句块。
1 | public class Cleanup { |
异常匹配
抛出异常的时候,异常处理系统会按照代码的书写顺序找出”最近“的处理程序。查找的时候不要求抛出的异常同处理程序所声明的异常完全匹配。派生类的对象也可以匹配其基类的处理程序。如果把捕获基类的catch子句放在最前面,就会把派生类的异常全给”屏蔽“掉。
其他可选方式
有时候不知道该如何处理”被检查的异常”,可以采取下面的措施
- 把异常从main传给控制台
- 把被检查的异常包装进RuntimeException里面
- 直接创建自己RuntimeException的子类。
异常使用指南
应该在下列情况下使用异常:
- 在恰当的级别处理问题(在知道该如何处理的情况下才捕获异常)。
- 解决问题并且重新调用产生异常的方法。
- 进行少许修补,然后绕过异常发生的地方继续执行
- 用别的数据进行计算,以代替方法预计会返回的值。
- 把当前运行环境下能做的事情尽量做完,然后把相同的异常重抛到更高层。
- 把当前运行环境下能做的事情尽量做完,然后把不同的异常抛到更高层。
- 终止程序。
- 进行简化。
- 让类库和程序更安全。
字符串
不可变String
String对象是不可变的。查看JDK文档你就会发现,String类中每一个看起来会修改String值的方法,实际上都是创建了一个全新的String对象,以包含修改后的字符串内容。而最初的String对象则丝毫未动。内部有final char[] values,没有方法修改其内容
重载“+”与StringBuilder
不可变性会带来一定的效率问题。为String对象重载的“+”操作符就是一个例子(“+”和“+=”是Java中仅有的两个重载过的操作符,而Java并不允许程序员重载任何操作符)。通过反编译代码(javap -c [类名]),我们可以发现它真正的工作情况:编译器自动引入了java.lang.StringBuilder类。虽然我们在源代码中并没有使用StringBuilder类,但是编译器却自作主张地使用了它,因为它更高效。调用StringBuilder的append()方法实现字符串的加操作,最后调用toString()生成结果。
现在,也许你会觉得可以随意使用String对象,反正编译器会为你自动优化性能。可是在这之前,让我们更深入地看看编译器能为我们优化到什么程度。通过循环分别通过追加创建一个字符串,反编译源码,我们可以看到:利用String创建时,编译器通过StringBuilder优化了字符串的创建,但是由于循环的存在,导致每次循环编译器都会创建一个StringBuilder对象;相比之下,利用StringBuilder创建字符串则只创建了一个StringBuilder对象,反编译的汇编指令也比前一个简洁的多。因此,当你为一个类编写toString()方法时,若字符串操作比较简单,那就可以信赖编译器,它会为你合理地构造最终的字符串结果。但是,如果你要在toString方法中使用循环,那么最好自己创建一个StringBuilder对象,用它来构造最终结果。如果拿不准该用哪种方式,随时可以用javap来分析你的程序。
StringBuilder是在Java SE5引入的,在这之前Java用的是StringBuffer。后者是线程安全的,因此开销会大些,所以在Java SE5/6中,字符串操作应该还会更快一些。
1 | public class Main{ |
对于1,编译器将做优化,str直接指向常量”abc”,而2、3则会使用StringBuilder的append方法优化。
无意识的递归
Java中的每个类从根本上都是继承自Object,标准容器类自然也不例外。因此容器类都有toString()方法,并且重写了该方法,使得它生成的String结果能够表达容器自身,以及容器所包含的对象。如果你希望toString()方法打印出对象的内存地址,也许你会考虑使用关键字this。但是,你会得到一串非常长的异常。这是因为编译器会将this转换成String,怎么转换呢,调用的就是toString()方法,发生了递归调用。因此,如果你真的想要打印出对象的内存地址,应该调用Object.toString()方法,而不是返回this。
String上的操作
String类有很多方法,在此不一一列举。在此,我们要注意一点,当需要改变字符串的内容时,String类的方法都会返回一个新的String对象。同时,如果内容没有发生改变,String的方法只是返回指向原对象的引用而已。
格式化输出
System.out.format();
Java SE5引入的format方法可用于PrintSteam或PrintWriter对象,其中包括System.out对象。format()方法模仿自C的printf()。如果你比较怀旧的话,也可以使用printf();
Formatter类
当你创建一个formatter对象的时候,需要向其构造器传递一些信息,告诉它最终的结果将向哪里输出。
格式化说明符
在插入数据时,如果想要控制空格与对齐,你需要更精细复杂的更是修饰符。以下是其抽象的语法:
1
%[argument_index$][flags][width][.precision]conversion
- 可选的 argument_index 是一个十进制整数,用于表明参数在参数列表中的位置。第一个参数由 “1$” 引用,第二个参数由 “2$” 引用,依此类推。
- 可选 flags 是修改输出格式的字符集。有效标志集取决于转换类型。在默认的情况下,数据是右对齐的,不过可以通过使用“-”编制来改变对齐方向。
- 可选 width 是一个非负十进制整数,表明要向输出中写入的最少字符数。必要时添加空格以达到指定长度。
- 可选 precision 是一个非负十进制整数,通常用来限制字符数。特定行为取决于转换类型。与width相对应用来指定最大尺寸。precision的意义也不同。在将precision应用于String时,它表示打印String时输出字符串的最大数量。而在将precision应用于浮点数时,它表示小数部分要显示出来的位数(默认是6位小数),如果小数位过多则舍入,太少则在尾补零。由于整数没有小数部分,所以precision无法应用于整数。
- 所需 conversion 是一个表明应该如何格式化参数的字符。给定参数的有效转换集取决于参数的数据类型。
Formatter转换
类似于C语言中printf()的那些特殊的占位符,如%d,表示整数型。
String.format()
Java SE5也参考了C中的sprintf()方法,以生成格式化的String对象。String.format()是一个static方法,它接受与Formatter.format()方法一样的参数,但是返回一个String对象。当你只需要使用format()方法一次时,String.format()用起来很方便。其实,在String.format()内部,它也是创建了一个Formatter对象,然后将你传入的参数转给该Formatter。不过,与其自己做这些事情,不如使用便捷的String.format()方法,何况这样的代码更清晰易读。
正则表达式
Java中,\\的意思是“我要插入一个正则表达式的反斜线,以后的字符具有特殊的意义”,如果想插入普通的反斜线,则应该是\\\\
字符
| 构造 | 匹配 |
|---|---|
| x | 字符 x |
\\ |
两个反斜线表示反斜线字符 |
| \xhh | 带有十六进制值 0x 的字符 hh |
| \uhhhh | 带有十六进制值 0x 的字符 hhhh |
| \t | 制表符 (‘\u0009’) |
| \n | 新行(换行)符 (‘\u000A’) |
| \r | 回车符 (‘\u000D’) |
| \f | 换页符 (‘\u000C’) |
| \a | 报警 (bell) 符 (‘\u0007’) |
| \e | 转义符 (‘\u001B’) |
| \cx | 对应于 x 的控制符 |
字符类
| 构造 | 匹配 |
|---|---|
| [abc] | a、b 或 c(简单类) |
| [^abc] | 任何字符,除了 a、b 或 c(否定) |
| [a-zA-Z] | a 到 z 或 A 到 Z,两头的字母包括在内(范围) |
| [a-d[m-p]] | a 到 d 或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] | d、e 或 f(交集) |
| [a-z&&[^bc]] | a 到 z,除了 b 和 c:[ad-z](减去) |
| [a-z&&[^m-p]] | a 到 z,而非 m 到 p:[a-lq-z](减去) |
预定义字符类
| 构造 | 匹配 |
|---|---|
| . | 任何字符(与行结束符可能匹配也可能不匹配) |
| \d | 数字:[0-9] |
| \D | 非数字: [^0-9] |
| \s | 空白字符:[ \t\n\x0B\f\r] |
| \S | 非空白字符:[^\s] |
| \w | 单词字符:[a-zA-Z_0-9] |
| \W | 非单词字符:[^\w] |
POSIX 字符类(仅 US-ASCII)
| 构造 | 匹配 |
|---|---|
| \p{Lower} | 小写字母字符:[a-z] |
| \p{Upper} | 大写字母字符:[A-Z] |
| \p{ASCII} | 所有 ASCII:[\x00-\x7F] |
| \p{Alpha} | 字母字符:[\p{Lower}\p{Upper}] |
| \p{Digit} | 十进制数字:[0-9] |
| \p{Alnum} | 字母数字字符:[\p{Alpha}\p{Digit}] |
| \p{Punct} | 标点符号:!”#$%&’()*+,-./:;?@[]^_`{}~以及竖线和反斜线 |
| \p{Graph} | 可见字符:[\p{Alnum}\p{Punct}] |
| \p{Print} | 可打印字符:[\p{Graph}\x20] |
| \p{Blank} | 空格或制表符:[ \t] |
| \p{Cntrl} | 控制字符:[\x00-\x1F\x7F] |
| \p{XDigit} | 十六进制数字:[0-9a-fA-F] |
| \p{Space} | 空白字符:[ \t\n\x0B\f\r] |
边界匹配器
| 构造 | 匹配 |
|---|---|
| ^ | 行的开头 |
| $ | 行的结尾 |
| \b | 单词边界 |
| \B | 非单词边界 |
| \A | 输入的开头 |
| \G | 上一个匹配的结尾 |
| \Z | 输入的结尾,仅用于最后的结束符(如果有的话) |
| \z | 输入的结尾 |
数量词
| 贪婪型 | 勉强型 | 占有型 | 匹配 |
|---|---|---|---|
| X? | X?? | X?+ | X,一次或一次也没有 |
| X* | X*? | X*+ | X,零次或多次 |
| X+ | X+? | X++ | X,一次或多次 |
| X{n} | X{n}? | X{n}+ | X,恰好 n 次 |
| X{n,} | X{n,}? | X{n,}+ | X,至少 n 次 |
| X{n,m} | X{n,m}? | X{n,m}+ | X,至少 n 次,但是不超过 m 次 |
占有型只有Java中才有
逻辑运算符
- XY : X 后跟 Y
- X|Y : X 或 Y
- (X) : X,作为捕获组
典型的调用顺序是
1 | Pattern p = Pattern.compile("a*b"); |
Pattern常用方法
| 方法声明 | 说明 |
|---|---|
| static Pattern compile(String regex) | 将给定的正则表达式编译到模式中。 |
| static Pattern compile(String regex, int flags) | 将给定的正则表达式编译到具有给定标志的模式中。 |
| Matcher matcher(CharSequence input) | 创建匹配给定输入与此模式的匹配器。 |
| static boolean matches(String regex, CharSequence input) | 编译给定正则表达式并尝试将给定输入与其匹配。 |
| String[] split(CharSequence input) | 围绕此模式的匹配拆分给定输入序列。 |
| String[] split(CharSequence input, int limit) | 围绕此模式的匹配拆分给定输入序列。 |
Pattern标记
| 标记 | 说明 |
|---|---|
| static int CANON_EQ | 启用规范等价。当且仅当完全规范分解相匹配时,就认为它们是匹配的,指定此标记a\u030A就会匹配? |
| static int CASE_INSENSITIVE(?i) | 启用不区分大小写的匹配。 |
| static int COMMENTS(?x) | 模式中允许空白和注释。空白和以#开始的注释都会被忽略 |
| static int DOTALL(?s) | 启用 dotall 模式。.可以匹配任何字符,包括行结束符。默认情况下,此表达式不匹配行结束符。 |
| static int LITERAL | 启用模式的字面值解析。指定此标志后,输入序列中的元字符或转义序列不具有任何特殊意义。 |
| static int MULTILINE(?m) | 启用多行模式。仅分别在行结束符前后匹配,或者在输入序列的结尾处匹配。默认情况下,这些表达式仅在整个输入序列的开头和结尾处匹配。 |
| static int UNICODE_CASE(?u) | 启用 Unicode 感知的大小写折叠。 |
| static int UNIX_LINES(?d) | 启用 Unix 行模式。在此模式中,.、^ 和 $ 的行为中仅识别 ‘\n’ 行结束符。 |
| Pattern.CASE_INSENSITIVE、Pattern.MULTILINE、Pattern.COMMENTS这三个标记特别有用。compile(String regex, int flags) 中的标记flags还可以用或( | )来组合。 |
Matcher常用方法
| 方法声明 | 说明 |
|---|---|
| boolean matches() | 尝试将整个区域与模式匹配。 |
| boolean lookingAt() | 尝试将从区域开头开始的输入序列与该模式匹配。 |
| boolean find() | 尝试查找与该模式匹配的输入序列的下一个子序列。 |
| boolean find(int start) | 重置此匹配器,然后从指定索引开始的下一个子序列尝试查找匹配该模式。 |
| int groupCount() | 返回此匹配器模式中的捕获组数。不包括0组 |
| String group() | 返回由以前匹配操作所匹配的输入子序列。相当于group(0) |
| String group(int group) | 返回在以前匹配操作期间由给定组捕获的输入子序列。 |
| int start() | 返回以前匹配的初始索引。相当于start(0) |
| int start(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引。 |
| int end() | 返回最后匹配字符之后的偏移量。相当于end(0) |
| int end(int group) | 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
| String replaceFirst(String replacement) | 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| String replaceAll(String replacement) | 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| Matcher appendReplacement(StringBuffer sb, String replacement) | 从添加位置(一般为0,append开头的其它方法会改变这个值)到start()-1字符串添加到缓存;添加替换字符串到缓存区;将添加位置设置为end() |
| StringBuffer appendTail(StringBuffer sb) | 从添加位置开始添加到缓冲区。可以在一次或多次调用 appendReplacement 方法后调用它来复制剩余的输入序列。 |
| Matcher reset() | 重置匹配器到当前字符序列的起始位置 |
| Matcher reset(CharSequence input) | 重置此具有新输入序列的匹配器。 |
组是用括号划分的正则表达式,可以根据组的编号来引用某个组,组号为0表示整个表达式,组号1表示第一个括号括起来的组。A(B(C))D 组0是ABCD,组1是BC,组2是C。groupCount() 返回的组数不包括0组。只有三种是匹配操作:matches(),lookingAt(),find(),这三个方法如果匹配成功,会改变下一次匹配的其实索引。
扫描输入
Java SE5新增了Scanner类。Scanner的构造器可以接受任何类型的输入对象,如File对象,InputStream,String对象。所有基本类型(除char外)包括BigDecimal和BigInteger,Scanner类都有next和hasnext方法。
Scanner定界符
在默认情况下,Scanner更具空白字符对输入进行分词,但是你可以用正则表达式指定自己所需的定界符。
scanner.useDelimiter("\\s*,\\s*");//使用逗号作为界定符用正则表达式扫描
除了能够扫描基本类型之外,你还可以使用自定义的正则表达式进行扫描,这在扫描复杂数据是非常有用。
1 | Scanner sc = new Scanner(System.in); |
StringTokenizer
基本上,我们可以放心的说,StringTokenizer已经可以废弃不用了。